Logistic Regression
Contents
Logistic Regression#
Imports#
from fastcore.all import *
import numpy as np
import scipy as sp
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import random
import nltk
import re
import string
from sklearn.linear_model import LogisticRegression
from sklearn import metrics
from nltk.corpus import twitter_samples
from rich.console import Console
from nltk.corpus import stopwords # module for stop words that come with NLTK
from nltk.stem import PorterStemmer # module for stemming
from nltk.tokenize import TweetTokenizer # module for tokenizing strings
sns.set()
console = Console()
Download Dataset#
nltk.download('twitter_samples')
nltk.download('stopwords')
[nltk_data] Downloading package twitter_samples to
[nltk_data] /home/rahul.saraf/nltk_data...
[nltk_data] Package twitter_samples is already up-to-date!
[nltk_data] Downloading package stopwords to
[nltk_data] /home/rahul.saraf/nltk_data...
[nltk_data] Package stopwords is already up-to-date!
True
L(twitter_samples.docs())[0]
{'contributors': None,
'coordinates': None,
'text': 'hopeless for tmr :(',
'user': {'screen_name': 'yuwraxkim',
'time_zone': 'Jakarta',
'profile_background_image_url': 'http://pbs.twimg.com/profile_background_images/585476378365014016/j1mvQu3c.png',
'profile_background_image_url_https': 'https://pbs.twimg.com/profile_background_images/585476378365014016/j1mvQu3c.png',
'default_profile_image': False,
'url': None,
'profile_text_color': '000000',
'following': False,
'listed_count': 3,
'entities': {'description': {'urls': []}},
'utc_offset': 25200,
'profile_sidebar_border_color': '000000',
'name': 'yuwra ✈ ',
'favourites_count': 196,
'followers_count': 1281,
'location': 'wearegsd;favor;pucukfams;barbx',
'protected': False,
'notifications': False,
'profile_image_url_https': 'https://pbs.twimg.com/profile_images/622631732399898624/kmYsX_k1_normal.jpg',
'profile_use_background_image': True,
'profile_image_url': 'http://pbs.twimg.com/profile_images/622631732399898624/kmYsX_k1_normal.jpg',
'lang': 'id',
'statuses_count': 19710,
'friends_count': 1264,
'profile_banner_url': 'https://pbs.twimg.com/profile_banners/3078803375/1433287528',
'geo_enabled': True,
'is_translator': False,
'contributors_enabled': False,
'profile_sidebar_fill_color': '000000',
'created_at': 'Sun Mar 08 05:43:40 +0000 2015',
'verified': False,
'profile_link_color': '000000',
'is_translation_enabled': False,
'has_extended_profile': False,
'id_str': '3078803375',
'follow_request_sent': False,
'profile_background_color': '000000',
'default_profile': False,
'profile_background_tile': True,
'id': 3078803375,
'description': '⇨ [V] TravelGency █ 2/4 Goddest from Girls Day █ 92L █ sucrp'},
'retweet_count': 0,
'favorited': False,
'entities': {'hashtags': [], 'user_mentions': [], 'urls': [], 'symbols': []},
'source': '<a href="https://mobile.twitter.com" rel="nofollow">Mobile Web (M2)</a>',
'truncated': False,
'geo': None,
'in_reply_to_status_id_str': None,
'is_quote_status': False,
'in_reply_to_user_id_str': None,
'place': None,
'in_reply_to_status_id': None,
'in_reply_to_screen_name': None,
'lang': 'en',
'retweeted': False,
'in_reply_to_user_id': None,
'created_at': 'Fri Jul 24 10:42:49 +0000 2015',
'metadata': {'iso_language_code': 'en', 'result_type': 'recent'},
'favorite_count': 0,
'id_str': '624530164626534400',
'id': 624530164626534400}
ptweets = twitter_samples.strings('positive_tweets.json')
ntweets = twitter_samples.strings('negative_tweets.json')
len(ptweets), len(ntweets)
(5000, 5000)
console.print(ptweets[random.randint(0,5000)], style='green')
console.print(ntweets[random.randint(0,5000)], style='red')
Hi BAM ! @BarsAndMelody Can you follow my bestfriend @969Horan696 ? She loves you a lot :) See you in Warsaw <3 Love you <3 x23
Mtaani tunaita pussy viazi choma and we still get laid :-(
Preprocessing#
What are we going to do?
Remove hyperlinks, twitter marks and styles
Tokenize
Remove Stopwords
Stemming
Remove hyperlinks, twitter marks and styles#
df = pd.DataFrame({'positive':ptweets, 'negative':ntweets})\
.unstack().reset_index().drop(columns=['level_1'])\
.rename(columns={0:'Tweet', 'level_0':'class'})
with pd.option_context('max_colwidth', 0):
display(df)
| class | Tweet | |
|---|---|---|
| 0 | positive | #FollowFriday @France_Inte @PKuchly57 @Milipol_Paris for being top engaged members in my community this week :) |
| 1 | positive | @Lamb2ja Hey James! How odd :/ Please call our Contact Centre on 02392441234 and we will be able to assist you :) Many thanks! |
| 2 | positive | @DespiteOfficial we had a listen last night :) As You Bleed is an amazing track. When are you in Scotland?! |
| 3 | positive | @97sides CONGRATS :) |
| 4 | positive | yeaaaah yippppy!!! my accnt verified rqst has succeed got a blue tick mark on my fb profile :) in 15 days |
| ... | ... | ... |
| 9995 | negative | I wanna change my avi but uSanele :( |
| 9996 | negative | MY PUPPY BROKE HER FOOT :( |
| 9997 | negative | where's all the jaebum baby pictures :(( |
| 9998 | negative | But but Mr Ahmad Maslan cooks too :( https://t.co/ArCiD31Zv6 |
| 9999 | negative | @eawoman As a Hull supporter I am expecting a misserable few weeks :-( |
10000 rows × 2 columns
df.iloc[2777+5000]
class negative
Tweet @Camy19994 FOLLOWED ME THANKS, AND\n@justinbie...
Name: 7777, dtype: object
tweet = df.iloc[0]['Tweet']
remove_old_style = lambda tweet: re.sub(r'^RT[\s]+', '', tweet)
remove_url = lambda tweet: re.sub(r'https?://[^\s\n\r]+', '', tweet)
remove_hash = lambda tweet: re.sub(r'#', '', tweet)
tokenizer = TweetTokenizer(preserve_case=False, strip_handles=True,
reduce_len=True)
stopwords_english = stopwords.words('english')
stemmer = PorterStemmer()
skip_words = stopwords_english+list(string.punctuation)
# stopwords_english
# tweet, set(tokenizer.tokenize(remove_hash(tweet))) - set(stopwords_english)
def process_tweet(tweet):
clean_tweet = remove_hash(remove_url(remove_old_style(tweet)))
tokens = tokenizer.tokenize(clean_tweet)
return [stemmer.stem(word) for word in tokens
if word not in skip_words]
df['PTweet']=df['Tweet'].apply(process_tweet)
df['PTweet']
0 [followfriday, top, engag, member, commun, wee...
1 [hey, jame, odd, :/, pleas, call, contact, cen...
2 [listen, last, night, :), bleed, amaz, track, ...
3 [congrat, :)]
4 [yeaaah, yipppi, accnt, verifi, rqst, succeed,...
...
9995 [wanna, chang, avi, usanel, :(]
9996 [puppi, broke, foot, :(]
9997 [where', jaebum, babi, pictur, :(]
9998 [mr, ahmad, maslan, cook, :(]
9999 [hull, support, expect, misser, week, :-(]
Name: PTweet, Length: 10000, dtype: object
toks = df['PTweet'].sum()
Feature Engineering#
Building Frequency Dictionary#
df.loc[0,'PTweet']
def contains_tok(tweet_tokens, tok):
in_tokens = False
if tok in tweet_tokens: in_tokens = True
return in_tokens
df[df.apply(lambda row: contains_tok(row['PTweet'], toks[1]), axis=1)]['class'].value_counts().to_dict()
# contains_tok(df.loc[0,'PTweet'], toks[0])
{'positive': 32, 'negative': 6}
toks = list(set(df['PTweet'].sum()))
toks[:10]
['children',
'latin',
'bilal',
'leno',
'savag',
'hyung',
'braxton',
'statement',
'convinc',
'therefor']
# toks[:10]
pd.DataFrame([{'word':tok,
**df[df.apply(lambda row: contains_tok(row['PTweet'], tok), axis=1)]['class'].value_counts().to_dict()}
for tok in toks[:10]]).fillna(0).set_index('word')
| positive | negative | |
|---|---|---|
| word | ||
| children | 3.0 | 2.0 |
| latin | 3.0 | 0.0 |
| bilal | 0.0 | 1.0 |
| leno | 0.0 | 1.0 |
| savag | 1.0 | 0.0 |
| hyung | 0.0 | 1.0 |
| braxton | 0.0 | 1.0 |
| statement | 1.0 | 1.0 |
| convinc | 0.0 | 3.0 |
| therefor | 0.0 | 1.0 |
def build_freqs(df):
toks = list(set(df['PTweet'].sum()))
return pd.DataFrame([{'word':tok,
**df[df.apply(lambda row: contains_tok(row['PTweet'], tok), axis=1)]['class'].value_counts().to_dict()}
for tok in toks]).fillna(0).set_index('word')
df_freq=build_freqs(df); df_freq.head()
| positive | negative | |
|---|---|---|
| word | ||
| children | 3.0 | 2.0 |
| latin | 3.0 | 0.0 |
| bilal | 0.0 | 1.0 |
| leno | 0.0 | 1.0 |
| savag | 1.0 | 0.0 |
df_freq.describe()
| positive | negative | |
|---|---|---|
| count | 10507.000000 | 10507.000000 |
| mean | 3.172361 | 3.077567 |
| std | 37.991689 | 44.787129 |
| min | 0.000000 | 0.000000 |
| 25% | 0.000000 | 0.000000 |
| 50% | 1.000000 | 1.000000 |
| 75% | 1.000000 | 1.000000 |
| max | 3541.000000 | 4422.000000 |
df_freq.sort_values(by='positive', ascending=False)
| positive | negative | |
|---|---|---|
| word | ||
| :) | 3541.0 | 2.0 |
| :-) | 669.0 | 0.0 |
| thank | 636.0 | 105.0 |
| :d | 628.0 | 0.0 |
| follow | 365.0 | 169.0 |
| ... | ... | ... |
| 💎 | 0.0 | 1.0 |
| gate | 0.0 | 1.0 |
| goodmus | 0.0 | 4.0 |
| 322 | 0.0 | 1.0 |
| 3a2ad | 0.0 | 1.0 |
10507 rows × 2 columns
df_freq.sort_values(by='negative', ascending=False)
| positive | negative | |
|---|---|---|
| word | ||
| :( | 1.0 | 4422.0 |
| :-( | 0.0 | 481.0 |
| i'm | 173.0 | 318.0 |
| miss | 27.0 | 296.0 |
| ... | 253.0 | 284.0 |
| ... | ... | ... |
| swasa | 1.0 | 0.0 |
| soph | 1.0 | 0.0 |
| ef | 1.0 | 0.0 |
| cocoar | 1.0 | 0.0 |
| kw | 2.0 | 0.0 |
10507 rows × 2 columns
Scoring Tweets#
tweet_token=df['PTweet'][0]
df_freq.loc[tweet_token].sum().to_dict()
{'positive': 3737.0, 'negative': 69.0}
# pd.DataFrame(df.apply(lambda row: ,axis=1))
def score_tweet(tweet_tokens):
l = df_freq.loc[tweet_tokens].sum().tolist()
l.append(1.0)
return l
score_tweet(tweet_token)
[3737.0, 69.0, 1.0]
df['positive'], df['negative'], df['bias']=zip(*df['PTweet'].map(score_tweet))
df
| class | Tweet | PTweet | positive | negative | bias | |
|---|---|---|---|---|---|---|
| 0 | positive | #FollowFriday @France_Inte @PKuchly57 @Milipol... | [followfriday, top, engag, member, commun, wee... | 3737.0 | 69.0 | 1.0 |
| 1 | positive | @Lamb2ja Hey James! How odd :/ Please call our... | [hey, jame, odd, :/, pleas, call, contact, cen... | 4448.0 | 473.0 | 1.0 |
| 2 | positive | @DespiteOfficial we had a listen last night :)... | [listen, last, night, :), bleed, amaz, track, ... | 3728.0 | 159.0 | 1.0 |
| 3 | positive | @97sides CONGRATS :) | [congrat, :)] | 3562.0 | 4.0 | 1.0 |
| 4 | positive | yeaaaah yippppy!!! my accnt verified rqst has... | [yeaaah, yipppi, accnt, verifi, rqst, succeed,... | 3878.0 | 273.0 | 1.0 |
| ... | ... | ... | ... | ... | ... | ... |
| 9995 | negative | I wanna change my avi but uSanele :( | [wanna, chang, avi, usanel, :(] | 55.0 | 4546.0 | 1.0 |
| 9996 | negative | MY PUPPY BROKE HER FOOT :( | [puppi, broke, foot, :(] | 3.0 | 4439.0 | 1.0 |
| 9997 | negative | where's all the jaebum baby pictures :(( | [where', jaebum, babi, pictur, :(] | 34.0 | 4490.0 | 1.0 |
| 9998 | negative | But but Mr Ahmad Maslan cooks too :( https://t... | [mr, ahmad, maslan, cook, :(] | 9.0 | 4434.0 | 1.0 |
| 9999 | negative | @eawoman As a Hull supporter I am expecting a ... | [hull, support, expect, misser, week, :-(] | 116.0 | 565.0 | 1.0 |
10000 rows × 6 columns
df_freq
| positive | negative | |
|---|---|---|
| word | ||
| children | 3.0 | 2.0 |
| latin | 3.0 | 0.0 |
| bilal | 0.0 | 1.0 |
| leno | 0.0 | 1.0 |
| savag | 1.0 | 0.0 |
| ... | ... | ... |
| smoak | 1.0 | 0.0 |
| siguro | 1.0 | 0.0 |
| kapan | 0.0 | 1.0 |
| fever | 2.0 | 7.0 |
| 3a2ad | 0.0 | 1.0 |
10507 rows × 2 columns
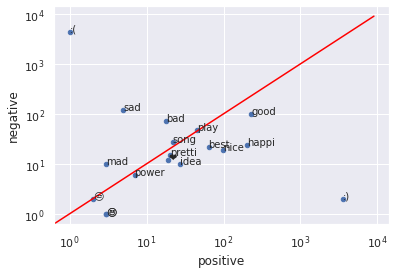
Visualizing Words#
keys = ['happi', 'merri', 'nice', 'good', 'bad', 'sad', 'mad', 'best', 'pretti',
'❤', ':)', ':(', '😒', '😬', '😄', '😍', '♛',
'song', 'idea', 'power', 'play', 'magnific']
sel_keys = [ k for k in keys if k in df_freq.index]
sel_keys
['happi',
'merri',
'nice',
'good',
'bad',
'sad',
'mad',
'best',
'pretti',
'❤',
':)',
':(',
'😒',
'😬',
'😄',
'😍',
'♛',
'song',
'idea',
'power',
'play',
'magnific']
sel_df = df_freq.loc[sel_keys]
%matplotlib inline
fig, ax = plt.subplots()
sel_df.plot.scatter(x='positive', y='negative', loglog=True, ax=ax)
for row in sel_df.iterrows():
ax.annotate(row[0], (row[1]['positive'], row[1]['negative']))
ax.plot([0, 9000], [0, 9000], color = 'red')
# fig.canvas.draw()
*c* argument looks like a single numeric RGB or RGBA sequence, which should be avoided as value-mapping will have precedence in case its length matches with *x* & *y*. Please use the *color* keyword-argument or provide a 2D array with a single row if you intend to specify the same RGB or RGBA value for all points.
[<matplotlib.lines.Line2D at 0x147a3b2b1670>]
Modeling- Logistics Regression#
df.head()
| class | Tweet | PTweet | positive | negative | bias | |
|---|---|---|---|---|---|---|
| 0 | positive | #FollowFriday @France_Inte @PKuchly57 @Milipol... | [followfriday, top, engag, member, commun, wee... | 3737.0 | 69.0 | 1.0 |
| 1 | positive | @Lamb2ja Hey James! How odd :/ Please call our... | [hey, jame, odd, :/, pleas, call, contact, cen... | 4448.0 | 473.0 | 1.0 |
| 2 | positive | @DespiteOfficial we had a listen last night :)... | [listen, last, night, :), bleed, amaz, track, ... | 3728.0 | 159.0 | 1.0 |
| 3 | positive | @97sides CONGRATS :) | [congrat, :)] | 3562.0 | 4.0 | 1.0 |
| 4 | positive | yeaaaah yippppy!!! my accnt verified rqst has... | [yeaaah, yipppi, accnt, verifi, rqst, succeed,... | 3878.0 | 273.0 | 1.0 |
df.iloc[:4000]
df.iloc[5000:9000]
| class | Tweet | PTweet | positive | negative | bias | |
|---|---|---|---|---|---|---|
| 5000 | negative | hopeless for tmr :( | [hopeless, tmr, :(] | 2.0 | 4427.0 | 1.0 |
| 5001 | negative | Everything in the kids section of IKEA is so c... | [everyth, kid, section, ikea, cute, shame, i'm... | 316.0 | 4917.0 | 1.0 |
| 5002 | negative | @Hegelbon That heart sliding into the waste ba... | [heart, slide, wast, basket, :(] | 20.0 | 4456.0 | 1.0 |
| 5003 | negative | “@ketchBurning: I hate Japanese call him "bani... | [“, hate, japanes, call, bani, :(, :(, ”] | 67.0 | 8962.0 | 1.0 |
| 5004 | negative | Dang starting next week I have "work" :( | [dang, start, next, week, work, :(] | 303.0 | 4690.0 | 1.0 |
| ... | ... | ... | ... | ... | ... | ... |
| 8995 | negative | Amelia didnt stalk my twitter :( | [amelia, didnt, stalk, twitter, :(] | 34.0 | 4479.0 | 1.0 |
| 8996 | negative | oh, i missed the broadcast. : ( | [oh, miss, broadcast] | 79.0 | 393.0 | 1.0 |
| 8997 | negative | i really can't stream on melon i feel useless :-( | [realli, can't, stream, melon, feel, useless, ... | 174.0 | 958.0 | 1.0 |
| 8998 | negative | I need to stop looking at old soccer pictures :( | [need, stop, look, old, soccer, pictur, :(] | 251.0 | 4703.0 | 1.0 |
| 8999 | negative | Got an interview for the job that I want but t... | [got, interview, job, want, rang, tuesday, int... | 236.0 | 4800.0 | 1.0 |
4000 rows × 6 columns
df['sentiment'] = 0
df.loc[df['class']=='positive', 'sentiment']=1
df
| class | Tweet | PTweet | positive | negative | bias | sentiment | |
|---|---|---|---|---|---|---|---|
| 0 | positive | #FollowFriday @France_Inte @PKuchly57 @Milipol... | [followfriday, top, engag, member, commun, wee... | 3737.0 | 69.0 | 1.0 | 1 |
| 1 | positive | @Lamb2ja Hey James! How odd :/ Please call our... | [hey, jame, odd, :/, pleas, call, contact, cen... | 4448.0 | 473.0 | 1.0 | 1 |
| 2 | positive | @DespiteOfficial we had a listen last night :)... | [listen, last, night, :), bleed, amaz, track, ... | 3728.0 | 159.0 | 1.0 | 1 |
| 3 | positive | @97sides CONGRATS :) | [congrat, :)] | 3562.0 | 4.0 | 1.0 | 1 |
| 4 | positive | yeaaaah yippppy!!! my accnt verified rqst has... | [yeaaah, yipppi, accnt, verifi, rqst, succeed,... | 3878.0 | 273.0 | 1.0 | 1 |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 9995 | negative | I wanna change my avi but uSanele :( | [wanna, chang, avi, usanel, :(] | 55.0 | 4546.0 | 1.0 | 0 |
| 9996 | negative | MY PUPPY BROKE HER FOOT :( | [puppi, broke, foot, :(] | 3.0 | 4439.0 | 1.0 | 0 |
| 9997 | negative | where's all the jaebum baby pictures :(( | [where', jaebum, babi, pictur, :(] | 34.0 | 4490.0 | 1.0 | 0 |
| 9998 | negative | But but Mr Ahmad Maslan cooks too :( https://t... | [mr, ahmad, maslan, cook, :(] | 9.0 | 4434.0 | 1.0 | 0 |
| 9999 | negative | @eawoman As a Hull supporter I am expecting a ... | [hull, support, expect, misser, week, :-(] | 116.0 | 565.0 | 1.0 | 0 |
10000 rows × 7 columns
train_df = pd.concat([df.iloc[:4000], df.iloc[5000:9000]]); train_df
| class | Tweet | PTweet | positive | negative | bias | sentiment | |
|---|---|---|---|---|---|---|---|
| 0 | positive | #FollowFriday @France_Inte @PKuchly57 @Milipol... | [followfriday, top, engag, member, commun, wee... | 3737.0 | 69.0 | 1.0 | 1 |
| 1 | positive | @Lamb2ja Hey James! How odd :/ Please call our... | [hey, jame, odd, :/, pleas, call, contact, cen... | 4448.0 | 473.0 | 1.0 | 1 |
| 2 | positive | @DespiteOfficial we had a listen last night :)... | [listen, last, night, :), bleed, amaz, track, ... | 3728.0 | 159.0 | 1.0 | 1 |
| 3 | positive | @97sides CONGRATS :) | [congrat, :)] | 3562.0 | 4.0 | 1.0 | 1 |
| 4 | positive | yeaaaah yippppy!!! my accnt verified rqst has... | [yeaaah, yipppi, accnt, verifi, rqst, succeed,... | 3878.0 | 273.0 | 1.0 | 1 |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 8995 | negative | Amelia didnt stalk my twitter :( | [amelia, didnt, stalk, twitter, :(] | 34.0 | 4479.0 | 1.0 | 0 |
| 8996 | negative | oh, i missed the broadcast. : ( | [oh, miss, broadcast] | 79.0 | 393.0 | 1.0 | 0 |
| 8997 | negative | i really can't stream on melon i feel useless :-( | [realli, can't, stream, melon, feel, useless, ... | 174.0 | 958.0 | 1.0 | 0 |
| 8998 | negative | I need to stop looking at old soccer pictures :( | [need, stop, look, old, soccer, pictur, :(] | 251.0 | 4703.0 | 1.0 | 0 |
| 8999 | negative | Got an interview for the job that I want but t... | [got, interview, job, want, rang, tuesday, int... | 236.0 | 4800.0 | 1.0 | 0 |
8000 rows × 7 columns
test_df = df.iloc[list(set(df.index.tolist()) - set(train_df.index.tolist()))]
test_df.tail()
| class | Tweet | PTweet | positive | negative | bias | sentiment | |
|---|---|---|---|---|---|---|---|
| 4995 | positive | @chriswiggin3 Chris, that's great to hear :) D... | [chri, that', great, hear, :), due, time, remi... | 4005.0 | 337.0 | 1.0 | 1 |
| 4996 | positive | @RachelLiskeard Thanks for the shout-out :) It... | [thank, shout-out, :), great, aboard] | 4349.0 | 129.0 | 1.0 | 1 |
| 4997 | positive | @side556 Hey! :) Long time no talk... | [hey, :), long, time, talk, ...] | 4075.0 | 556.0 | 1.0 | 1 |
| 4998 | positive | @staybubbly69 as Matt would say. WELCOME TO AD... | [matt, would, say, welcom, adulthood, ..., :)] | 4017.0 | 420.0 | 1.0 | 1 |
| 4999 | positive | @DanielOConnel18 you could say he will have eg... | [could, say, egg, face, :-)] | 776.0 | 154.0 | 1.0 | 1 |
Train test Split#
X = train_df[['bias', 'positive', 'negative']]
y = train_df['sentiment']
X_test = test_df[['bias', 'positive', 'negative']]
y_test = test_df['sentiment']
Model training#
model = LogisticRegression()
model.fit(X , y)
LogisticRegression()
Model Scoring#
model.coef_
array([[ 0.24050227, 0.00685412, -0.0077651 ]])
metrics.accuracy_score(y, model.predict(X)) # Score on training
0.992875
metrics.accuracy_score(y_test, model.predict(X_test))
0.994
Visualizing Model#
thetas = model.coef_.reshape(3,1)
array([0.00685412, 0.01370825, 0.02056237])
def negative(thetas, pos):
return ( -thetas[0] - thetas[1]*pos)/thetas[2]
def direction(thetas, pos):
return pos * thetas[2] / thetas[1]
# negative(thetas, np.array([1,2,3]))
# direction(thetas, np.array([1,2,3]))
28424.0
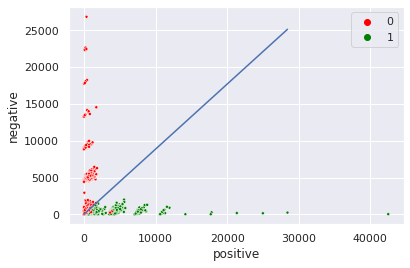
palette ={0:'red', 1:'green'}
offset=5000
ax = sns.scatterplot(data=df, x='positive',y='negative', hue='sentiment', palette=palette, marker='.')
pos = np.arange(0, int(X.abs().max().max()), 1); pos
sns.lineplot(pos, negative(thetas, pos), ax=ax)
# ax.arrow(offset, negative(thetas, offset), offset, direction(thetas, offset), head_width=500, head_length=500, fc='g', ec='g')
# # Plot a red line pointing to the negative direction
# ax.arrow(offset, negative(thetas, offset), -offset, -direction(thetas, offset), head_width=500, head_length=500, fc='r', ec='r')
/opt/anaconda/envs/aiking/lib/python3.9/site-packages/seaborn/_decorators.py:36: FutureWarning: Pass the following variables as keyword args: x, y. From version 0.12, the only valid positional argument will be `data`, and passing other arguments without an explicit keyword will result in an error or misinterpretation.
warnings.warn(
<AxesSubplot:xlabel='positive', ylabel='negative'>