Brand Choice Modelling
Contents
Brand Choice Modelling#
Imports#
import pandas as pd
import scipy as sp
import seaborn as sns
import matplotlib.pyplot as plt
import sklearn
import numpy as np
import pickle
import joblib
import itertools
from sklearn.linear_model import LogisticRegression
sns.set()
Read and Prepare Dataset#
df = pd.read_csv("purchase data.csv"); df.head()
| ID | Day | Incidence | Brand | Quantity | Last_Inc_Brand | Last_Inc_Quantity | Price_1 | Price_2 | Price_3 | ... | Promotion_3 | Promotion_4 | Promotion_5 | Sex | Marital status | Age | Education | Income | Occupation | Settlement size | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 200000001 | 1 | 0 | 0 | 0 | 0 | 0 | 1.59 | 1.87 | 2.01 | ... | 0 | 0 | 0 | 0 | 0 | 47 | 1 | 110866 | 1 | 0 |
| 1 | 200000001 | 11 | 0 | 0 | 0 | 0 | 0 | 1.51 | 1.89 | 1.99 | ... | 0 | 0 | 0 | 0 | 0 | 47 | 1 | 110866 | 1 | 0 |
| 2 | 200000001 | 12 | 0 | 0 | 0 | 0 | 0 | 1.51 | 1.89 | 1.99 | ... | 0 | 0 | 0 | 0 | 0 | 47 | 1 | 110866 | 1 | 0 |
| 3 | 200000001 | 16 | 0 | 0 | 0 | 0 | 0 | 1.52 | 1.89 | 1.98 | ... | 0 | 0 | 0 | 0 | 0 | 47 | 1 | 110866 | 1 | 0 |
| 4 | 200000001 | 18 | 0 | 0 | 0 | 0 | 0 | 1.52 | 1.89 | 1.99 | ... | 0 | 0 | 0 | 0 | 0 | 47 | 1 | 110866 | 1 | 0 |
5 rows × 24 columns
def do_clustering(df, pipeline, drop_cols=None, sel_cols=None, do_fit=False):
y = None
df_new = df.copy()
if drop_cols: df_new = df_new.drop(columns=drop_cols, axis=1)
df_filter = df_new.copy()
if sel_cols: df_filter = df_new[sel_cols]
if do_fit:y = pipeline.fit_predict(df_filter)
else: y = pipeline.predict(df_filter)
if 'pca' in pipeline.named_steps:
m = pipeline.named_steps['pca']
comp_names = [f"PCA{i+1}" for i in range(m.n_components)]
transform_df = df_filter.copy()
for step in pipeline.named_steps:
transform_df = pipeline.named_steps[step].transform(transform_df)
if step == "pca": break
pca_df = pd.DataFrame(transform_df,
columns=comp_names,
index=df_filter.index)
df_new = pd.concat([df_new, pca_df], axis=1)
df_new['y'] = y+1
return df_new, pipeline
pipeline = joblib.load("cluster_pipeline.pkl"); pipeline
sel_cols = ['Sex','Marital status','Age','Education','Income','Occupation','Settlement size']
df_segments, _ = do_clustering(df, pipeline, sel_cols=sel_cols)
names = {1:"Standard",
2:"Career-Focussed",
3:"Fewer-Opportunities",
4:"Well-off"}
df_segments['labels'] = df_segments['y'].map(names)
df_segments.head().T
| 0 | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
| ID | 200000001 | 200000001 | 200000001 | 200000001 | 200000001 |
| Day | 1 | 11 | 12 | 16 | 18 |
| Incidence | 0 | 0 | 0 | 0 | 0 |
| Brand | 0 | 0 | 0 | 0 | 0 |
| Quantity | 0 | 0 | 0 | 0 | 0 |
| Last_Inc_Brand | 0 | 0 | 0 | 0 | 0 |
| Last_Inc_Quantity | 0 | 0 | 0 | 0 | 0 |
| Price_1 | 1.59 | 1.51 | 1.51 | 1.52 | 1.52 |
| Price_2 | 1.87 | 1.89 | 1.89 | 1.89 | 1.89 |
| Price_3 | 2.01 | 1.99 | 1.99 | 1.98 | 1.99 |
| Price_4 | 2.09 | 2.09 | 2.09 | 2.09 | 2.09 |
| Price_5 | 2.66 | 2.66 | 2.66 | 2.66 | 2.66 |
| Promotion_1 | 0 | 0 | 0 | 0 | 0 |
| Promotion_2 | 1 | 0 | 0 | 0 | 0 |
| Promotion_3 | 0 | 0 | 0 | 0 | 0 |
| Promotion_4 | 0 | 0 | 0 | 0 | 0 |
| Promotion_5 | 0 | 0 | 0 | 0 | 0 |
| Sex | 0 | 0 | 0 | 0 | 0 |
| Marital status | 0 | 0 | 0 | 0 | 0 |
| Age | 47 | 47 | 47 | 47 | 47 |
| Education | 1 | 1 | 1 | 1 | 1 |
| Income | 110866 | 110866 | 110866 | 110866 | 110866 |
| Occupation | 1 | 1 | 1 | 1 | 1 |
| Settlement size | 0 | 0 | 0 | 0 | 0 |
| PCA1 | 0.362152 | 0.362152 | 0.362152 | 0.362152 | 0.362152 |
| PCA2 | -0.639557 | -0.639557 | -0.639557 | -0.639557 | -0.639557 |
| PCA3 | 1.462706 | 1.462706 | 1.462706 | 1.462706 | 1.462706 |
| PCA4 | -0.593242 | -0.593242 | -0.593242 | -0.593242 | -0.593242 |
| y | 3 | 3 | 3 | 3 | 3 |
| labels | Fewer-Opportunities | Fewer-Opportunities | Fewer-Opportunities | Fewer-Opportunities | Fewer-Opportunities |
features = "Brand|Price*|Promotion*|labels"
df_brand_choice = df_segments[df_segments.Incidence == 1].filter(regex=features).drop(columns=["Last_Inc_Brand"]).reset_index(drop=True); df_brand_choice.head()
| Brand | Price_1 | Price_2 | Price_3 | Price_4 | Price_5 | Promotion_1 | Promotion_2 | Promotion_3 | Promotion_4 | Promotion_5 | labels | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2 | 1.50 | 1.90 | 1.99 | 2.09 | 2.67 | 0 | 0 | 0 | 0 | 0 | Fewer-Opportunities |
| 1 | 5 | 1.39 | 1.90 | 1.91 | 2.12 | 2.62 | 1 | 0 | 0 | 0 | 1 | Fewer-Opportunities |
| 2 | 1 | 1.47 | 1.90 | 1.99 | 1.97 | 2.67 | 0 | 0 | 0 | 1 | 0 | Fewer-Opportunities |
| 3 | 4 | 1.21 | 1.35 | 1.99 | 2.16 | 2.68 | 1 | 1 | 0 | 0 | 0 | Fewer-Opportunities |
| 4 | 2 | 1.46 | 1.88 | 1.97 | 1.89 | 2.37 | 1 | 0 | 0 | 1 | 1 | Fewer-Opportunities |
df_brand_choice.filter(regex="Pr")
| Price_1 | Price_2 | Price_3 | Price_4 | Price_5 | Promotion_1 | Promotion_2 | Promotion_3 | Promotion_4 | Promotion_5 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1.50 | 1.90 | 1.99 | 2.09 | 2.67 | 0 | 0 | 0 | 0 | 0 |
| 1 | 1.39 | 1.90 | 1.91 | 2.12 | 2.62 | 1 | 0 | 0 | 0 | 1 |
| 2 | 1.47 | 1.90 | 1.99 | 1.97 | 2.67 | 0 | 0 | 0 | 1 | 0 |
| 3 | 1.21 | 1.35 | 1.99 | 2.16 | 2.68 | 1 | 1 | 0 | 0 | 0 |
| 4 | 1.46 | 1.88 | 1.97 | 1.89 | 2.37 | 1 | 0 | 0 | 1 | 1 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 14633 | 1.48 | 1.89 | 2.01 | 2.18 | 2.69 | 0 | 0 | 0 | 0 | 0 |
| 14634 | 1.35 | 1.57 | 2.02 | 2.21 | 2.70 | 1 | 1 | 0 | 0 | 0 |
| 14635 | 1.50 | 1.85 | 2.06 | 2.24 | 2.79 | 1 | 1 | 0 | 0 | 0 |
| 14636 | 1.42 | 1.51 | 1.97 | 2.24 | 2.78 | 0 | 0 | 0 | 0 | 0 |
| 14637 | 1.51 | 1.82 | 2.09 | 2.24 | 2.80 | 0 | 0 | 0 | 0 | 0 |
14638 rows × 10 columns
Brand choice probability#
model_brand = LogisticRegression(multi_class='multinomial', solver='sag')
model_brand.fit(df_brand_choice.filter(regex="Pr").values, df_brand_choice['Brand'].values)
LogisticRegression(multi_class='multinomial', solver='sag')
model_brand.coef_.shape
(5, 10)
df_brand_choice.filter(regex="Pr").columns.tolist(), df_brand_choice.Brand.unique().tolist()
(['Price_1',
'Price_2',
'Price_3',
'Price_4',
'Price_5',
'Promotion_1',
'Promotion_2',
'Promotion_3',
'Promotion_4',
'Promotion_5'],
[2, 5, 1, 4, 3])
df_brand_coeff = pd.DataFrame(model_brand.coef_, columns=df_brand_choice.filter(regex="Pr").columns.tolist(), index=model_brand.classes_)
fig, ax = plt.subplots(figsize=(12,6))
sns.heatmap(data=df_brand_coeff, cmap="RdYlBu", annot=True, ax=ax)
<AxesSubplot:>
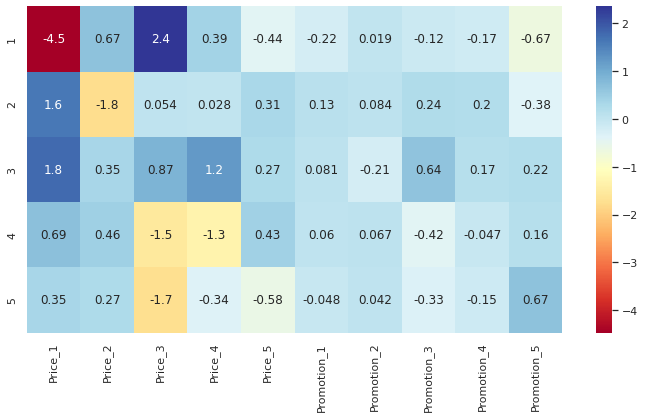
df_brand_coeff.loc[1, 'Price_1']
-4.469319087099478
prices = np.arange(0.5, 3.5,0.01); prices.shape, prices
((300,),
array([0.5 , 0.51, 0.52, 0.53, 0.54, 0.55, 0.56, 0.57, 0.58, 0.59, 0.6 ,
0.61, 0.62, 0.63, 0.64, 0.65, 0.66, 0.67, 0.68, 0.69, 0.7 , 0.71,
0.72, 0.73, 0.74, 0.75, 0.76, 0.77, 0.78, 0.79, 0.8 , 0.81, 0.82,
0.83, 0.84, 0.85, 0.86, 0.87, 0.88, 0.89, 0.9 , 0.91, 0.92, 0.93,
0.94, 0.95, 0.96, 0.97, 0.98, 0.99, 1. , 1.01, 1.02, 1.03, 1.04,
1.05, 1.06, 1.07, 1.08, 1.09, 1.1 , 1.11, 1.12, 1.13, 1.14, 1.15,
1.16, 1.17, 1.18, 1.19, 1.2 , 1.21, 1.22, 1.23, 1.24, 1.25, 1.26,
1.27, 1.28, 1.29, 1.3 , 1.31, 1.32, 1.33, 1.34, 1.35, 1.36, 1.37,
1.38, 1.39, 1.4 , 1.41, 1.42, 1.43, 1.44, 1.45, 1.46, 1.47, 1.48,
1.49, 1.5 , 1.51, 1.52, 1.53, 1.54, 1.55, 1.56, 1.57, 1.58, 1.59,
1.6 , 1.61, 1.62, 1.63, 1.64, 1.65, 1.66, 1.67, 1.68, 1.69, 1.7 ,
1.71, 1.72, 1.73, 1.74, 1.75, 1.76, 1.77, 1.78, 1.79, 1.8 , 1.81,
1.82, 1.83, 1.84, 1.85, 1.86, 1.87, 1.88, 1.89, 1.9 , 1.91, 1.92,
1.93, 1.94, 1.95, 1.96, 1.97, 1.98, 1.99, 2. , 2.01, 2.02, 2.03,
2.04, 2.05, 2.06, 2.07, 2.08, 2.09, 2.1 , 2.11, 2.12, 2.13, 2.14,
2.15, 2.16, 2.17, 2.18, 2.19, 2.2 , 2.21, 2.22, 2.23, 2.24, 2.25,
2.26, 2.27, 2.28, 2.29, 2.3 , 2.31, 2.32, 2.33, 2.34, 2.35, 2.36,
2.37, 2.38, 2.39, 2.4 , 2.41, 2.42, 2.43, 2.44, 2.45, 2.46, 2.47,
2.48, 2.49, 2.5 , 2.51, 2.52, 2.53, 2.54, 2.55, 2.56, 2.57, 2.58,
2.59, 2.6 , 2.61, 2.62, 2.63, 2.64, 2.65, 2.66, 2.67, 2.68, 2.69,
2.7 , 2.71, 2.72, 2.73, 2.74, 2.75, 2.76, 2.77, 2.78, 2.79, 2.8 ,
2.81, 2.82, 2.83, 2.84, 2.85, 2.86, 2.87, 2.88, 2.89, 2.9 , 2.91,
2.92, 2.93, 2.94, 2.95, 2.96, 2.97, 2.98, 2.99, 3. , 3.01, 3.02,
3.03, 3.04, 3.05, 3.06, 3.07, 3.08, 3.09, 3.1 , 3.11, 3.12, 3.13,
3.14, 3.15, 3.16, 3.17, 3.18, 3.19, 3.2 , 3.21, 3.22, 3.23, 3.24,
3.25, 3.26, 3.27, 3.28, 3.29, 3.3 , 3.31, 3.32, 3.33, 3.34, 3.35,
3.36, 3.37, 3.38, 3.39, 3.4 , 3.41, 3.42, 3.43, 3.44, 3.45, 3.46,
3.47, 3.48, 3.49]))
brand = 5
df_prices = pd.DataFrame({"mean":df_brand_choice.filter(regex="Price").mean(),
"min":df_brand_choice.filter(regex="Price").min(),
"max":df_brand_choice.filter(regex="Price").max()}).reset_index().melt(id_vars='index')
df_prices
| index | variable | value | |
|---|---|---|---|
| 0 | Price_1 | mean | 1.384559 |
| 1 | Price_2 | mean | 1.764717 |
| 2 | Price_3 | mean | 2.006694 |
| 3 | Price_4 | mean | 2.159658 |
| 4 | Price_5 | mean | 2.654296 |
| 5 | Price_1 | min | 1.100000 |
| 6 | Price_2 | min | 1.260000 |
| 7 | Price_3 | min | 1.870000 |
| 8 | Price_4 | min | 1.760000 |
| 9 | Price_5 | min | 2.110000 |
| 10 | Price_1 | max | 1.590000 |
| 11 | Price_2 | max | 1.900000 |
| 12 | Price_3 | max | 2.140000 |
| 13 | Price_4 | max | 2.260000 |
| 14 | Price_5 | max | 2.800000 |
regex="Price"
def get_df_summary(df_brand_choice, regex="Price"):
df = pd.DataFrame({"mean":df_brand_choice.filter(regex=regex).mean(),
"min":df_brand_choice.filter(regex=regex).min(),
"max":df_brand_choice.filter(regex=regex).max()}).reset_index().melt(id_vars='index')
df['id'] = df['index'].str.cat(df['variable'], sep="-")
df = df.drop(columns=['index', 'variable'], axis=1)
df = df.set_index('id').T.reset_index(drop=True)
return df
get_df_summary(df_brand_choice,regex="Promotion")
| id | Promotion_1-mean | Promotion_2-mean | Promotion_3-mean | Promotion_4-mean | Promotion_5-mean | Promotion_1-min | Promotion_2-min | Promotion_3-min | Promotion_4-min | Promotion_5-min | Promotion_1-max | Promotion_2-max | Promotion_3-max | Promotion_4-max | Promotion_5-max |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.372455 | 0.349638 | 0.043858 | 0.128091 | 0.04543 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
include_promo = "min"
brand = 5
df_brand_elasticity=pd.DataFrame()
df_brand_elasticity['prices'] = prices
df_brand_elasticity['promo']= 1
df_brand_elasticity['brand']= brand
df_brand_elasticity = df_brand_elasticity.join(get_df_summary(df_brand_choice,regex="Price")).ffill()
df_brand_elasticity = df_brand_elasticity.join(get_df_summary(df_brand_choice,regex="Promotion")).ffill()
for br in model_brand.classes_:
df_input = df_brand_elasticity.filter(regex=f"(Price.*mean|Promo.*{include_promo})").copy()
df_input[f"Price_{br}-mean"] = df_brand_elasticity.prices
probabilities = model_brand.predict_proba(df_input.values)
df_brand_elasticity.loc[:, f"Probabilities_{br}" ] = probabilities[:,br-1]
if br == brand: df_brand_elasticity.loc[:, f"Elasticity_{br}" ] = df_brand_coeff.loc[brand, f'Price_{brand}']*df_brand_elasticity.prices*(1- df_brand_elasticity[f"Probabilities_{br}"])
else: df_brand_elasticity.loc[:, f"Elasticity_{br}" ] = -1*df_brand_coeff.loc[brand, f'Price_{brand}']*df_brand_elasticity.prices*df_brand_elasticity[f"Probabilities_{br}"]
df_brand_elasticity
| prices | promo | brand | Price_1-mean | Price_2-mean | Price_3-mean | Price_4-mean | Price_5-mean | Price_1-min | Price_2-min | ... | Probabilities_1 | Elasticity_1 | Probabilities_2 | Elasticity_2 | Probabilities_3 | Elasticity_3 | Probabilities_4 | Elasticity_4 | Probabilities_5 | Elasticity_5 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.50 | 1 | 5 | 1.384559 | 1.764717 | 2.006694 | 2.159658 | 2.654296 | 1.1 | 1.26 | ... | 9.183243e-01 | 0.265457 | 0.853568 | 0.246738 | 0.002126 | 0.000615 | 0.652661 | 0.188662 | 0.709821 | -0.083881 |
| 1 | 0.51 | 1 | 5 | 1.384559 | 1.764717 | 2.006694 | 2.159658 | 2.654296 | 1.1 | 1.26 | ... | 9.143896e-01 | 0.269606 | 0.850910 | 0.250889 | 0.002180 | 0.000643 | 0.650092 | 0.191678 | 0.708717 | -0.085884 |
| 2 | 0.52 | 1 | 5 | 1.384559 | 1.764717 | 2.006694 | 2.159658 | 2.654296 | 1.1 | 1.26 | ... | 9.102819e-01 | 0.273657 | 0.848212 | 0.254997 | 0.002234 | 0.000672 | 0.647513 | 0.194661 | 0.707608 | -0.087901 |
| 3 | 0.53 | 1 | 5 | 1.384559 | 1.764717 | 2.006694 | 2.159658 | 2.654296 | 1.1 | 1.26 | ... | 9.059955e-01 | 0.277606 | 0.845475 | 0.259062 | 0.002290 | 0.000702 | 0.644924 | 0.197611 | 0.706493 | -0.089933 |
| 4 | 0.54 | 1 | 5 | 1.384559 | 1.764717 | 2.006694 | 2.159658 | 2.654296 | 1.1 | 1.26 | ... | 9.015243e-01 | 0.281448 | 0.842696 | 0.263083 | 0.002348 | 0.000733 | 0.642325 | 0.200529 | 0.705373 | -0.091980 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 295 | 3.45 | 1 | 5 | 1.384559 | 1.764717 | 2.006694 | 2.159658 | 2.654296 | 1.1 | 1.26 | ... | 7.788910e-07 | 0.000002 | 0.010487 | 0.020917 | 0.057650 | 0.114986 | 0.036948 | 0.073695 | 0.222011 | -1.551743 |
| 296 | 3.46 | 1 | 5 | 1.384559 | 1.764717 | 2.006694 | 2.159658 | 2.654296 | 1.1 | 1.26 | ... | 7.335952e-07 | 0.000001 | 0.010264 | 0.020532 | 0.056995 | 0.114010 | 0.036359 | 0.072730 | 0.220519 | -1.559226 |
| 297 | 3.47 | 1 | 5 | 1.384559 | 1.764717 | 2.006694 | 2.159658 | 2.654296 | 1.1 | 1.26 | ... | 6.909231e-07 | 0.000001 | 0.010046 | 0.020153 | 0.056344 | 0.113033 | 0.035777 | 0.071774 | 0.219033 | -1.566714 |
| 298 | 3.48 | 1 | 5 | 1.384559 | 1.764717 | 2.006694 | 2.159658 | 2.654296 | 1.1 | 1.26 | ... | 6.507233e-07 | 0.000001 | 0.009832 | 0.019781 | 0.055696 | 0.112056 | 0.035204 | 0.070826 | 0.217553 | -1.574206 |
| 299 | 3.49 | 1 | 5 | 1.384559 | 1.764717 | 2.006694 | 2.159658 | 2.654296 | 1.1 | 1.26 | ... | 6.128534e-07 | 0.000001 | 0.009623 | 0.019416 | 0.055053 | 0.111079 | 0.034638 | 0.069888 | 0.216080 | -1.581702 |
300 rows × 43 columns
df_brand_elasticity['Price_5-max'][0]
2.8
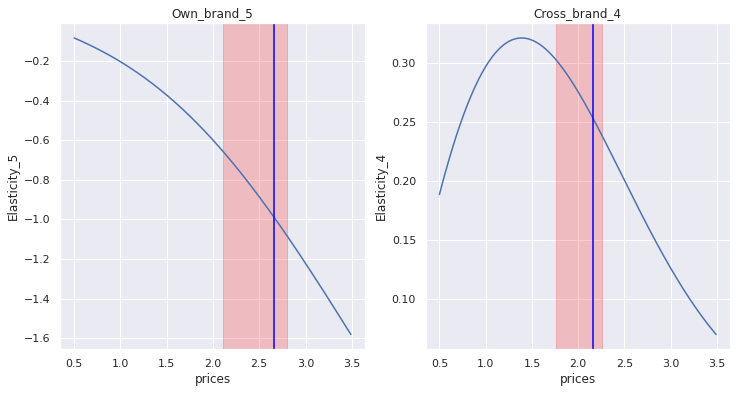
o = 5 #Own Brand
c = 4 #Cross Brand
fig, axes = plt.subplots(1,2, figsize=(12,6))
sns.lineplot(data=df_brand_elasticity, x="prices", y=f"Elasticity_{o}", ax=axes[0]).set(title=f"Own_brand_{o}")
axes[0].axvspan(df_brand_elasticity[f'Price_{o}-min'][0], df_brand_elasticity[f'Price_{o}-max'][0], alpha=.2, color='red')
axes[0].axvline(df_brand_elasticity[f'Price_{o}-mean'][0], color='blue')
sns.lineplot(data=df_brand_elasticity, x="prices", y=f"Elasticity_{c}", ax=axes[1]).set(title=f"Cross_brand_{c}")
axes[1].axvspan(df_brand_elasticity[f'Price_{c}-min'][0], df_brand_elasticity[f'Price_{c}-max'][0], alpha=.2, color='red')
axes[1].axvline(df_brand_elasticity[f'Price_{c}-mean'][0], color='blue')
<matplotlib.lines.Line2D at 0xf1f6c080eb0>
Brand choice probability by segments#
segments = df_segments['labels'].unique().tolist(); segments
segments.insert(0, None)
segments
[None, 'Fewer-Opportunities', 'Well-off', 'Career-Focussed', 'Standard']
def get_brand_elasticity_df(df_brand_choice, segment=None, brand=5, include_promo='min', max_iter=1000):
label = "Aggregate"
df = df_brand_choice.copy()
if segment:
label = segment
df = df_brand_choice[df_brand_choice['labels'] == segment].copy()
# Model Training
model_brand = LogisticRegression(multi_class='multinomial', solver='sag', max_iter=max_iter)
model_brand.fit(df.filter(regex="Pr").values, df['Brand'].values)
df_brand_coeff = pd.DataFrame(model_brand.coef_, columns=df.filter(regex="Pr").columns.tolist(), index=model_brand.classes_)
prices = np.arange(0.5, 3.5,0.01)
df_brand_elasticity = pd.DataFrame()
df_brand_elasticity['prices'] = prices
df_brand_elasticity['promo']= 1
df_brand_elasticity['brand']= brand
df_brand_elasticity = df_brand_elasticity.join(get_df_summary(df,regex="Price")).ffill()
df_brand_elasticity = df_brand_elasticity.join(get_df_summary(df,regex="Promotion")).ffill()
for br in model_brand.classes_:
df_input = df_brand_elasticity.filter(regex=f"(Price.*mean|Promo.*{include_promo})").copy()
df_input[f"Price_{br}-mean"] = df_brand_elasticity.prices
probabilities = model_brand.predict_proba(df_input.values)
df_brand_elasticity.loc[:, f"Probabilities_{br}" ] = probabilities[:,br-1]
if br == brand: df_brand_elasticity.loc[:, f"Elasticity_{br}" ] = df_brand_coeff.loc[brand, f'Price_{brand}']*df_brand_elasticity.prices*(1- df_brand_elasticity[f"Probabilities_{br}"])
else: df_brand_elasticity.loc[:, f"Elasticity_{br}" ] = -1*df_brand_coeff.loc[brand, f'Price_{brand}']*df_brand_elasticity.prices*df_brand_elasticity[f"Probabilities_{br}"]
df_brand_elasticity['label'] = label
return df_brand_elasticity
a = get_brand_elasticity_df(df_brand_choice,segment=segments[0])
a.head()
| prices | promo | brand | Price_1-mean | Price_2-mean | Price_3-mean | Price_4-mean | Price_5-mean | Price_1-min | Price_2-min | ... | Elasticity_1 | Probabilities_2 | Elasticity_2 | Probabilities_3 | Elasticity_3 | Probabilities_4 | Elasticity_4 | Probabilities_5 | Elasticity_5 | label | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.50 | 1 | 5 | 1.384559 | 1.764717 | 2.006694 | 2.159658 | 2.654296 | 1.1 | 1.26 | ... | 0.265461 | 0.853569 | 0.246742 | 0.002126 | 0.000614 | 0.652661 | 0.188665 | 0.709819 | -0.083883 | Aggregate |
| 1 | 0.51 | 1 | 5 | 1.384559 | 1.764717 | 2.006694 | 2.159658 | 2.654296 | 1.1 | 1.26 | ... | 0.269610 | 0.850911 | 0.250893 | 0.002179 | 0.000643 | 0.650092 | 0.191681 | 0.708715 | -0.085886 | Aggregate |
| 2 | 0.52 | 1 | 5 | 1.384559 | 1.764717 | 2.006694 | 2.159658 | 2.654296 | 1.1 | 1.26 | ... | 0.273662 | 0.848213 | 0.255001 | 0.002234 | 0.000672 | 0.647513 | 0.194664 | 0.707606 | -0.087903 | Aggregate |
| 3 | 0.53 | 1 | 5 | 1.384559 | 1.764717 | 2.006694 | 2.159658 | 2.654296 | 1.1 | 1.26 | ... | 0.277611 | 0.845475 | 0.259066 | 0.002290 | 0.000702 | 0.644924 | 0.197614 | 0.706491 | -0.089935 | Aggregate |
| 4 | 0.54 | 1 | 5 | 1.384559 | 1.764717 | 2.006694 | 2.159658 | 2.654296 | 1.1 | 1.26 | ... | 0.281453 | 0.842697 | 0.263087 | 0.002347 | 0.000733 | 0.642325 | 0.200531 | 0.705370 | -0.091982 | Aggregate |
5 rows × 44 columns
brands = [1,2,3,4,5]
df_brand_elasticity_all = pd.concat([get_brand_elasticity_df(df_brand_choice, segment=s, brand=b) for s,b in itertools.product(segments, brands)]).reset_index(drop=True)
df_brand_elasticity_all.shape
(7500, 44)