Predictive Analytics
Contents
Predictive Analytics#
Goal :-
What is likelihood that a customer will purchase?
If they do, How much they will spend?
Imports#
import pandas as pd
import numpy as np
import scipy as sp
import matplotlib.pyplot as plt
import seaborn as sns
import datetime as dt
from sklearn.cluster import AgglomerativeClustering
from scipy.cluster.hierarchy import dendrogram, linkage
from sklearn.pipeline import Pipeline, make_pipeline
from sklearn.preprocessing import StandardScaler, RobustScaler, FunctionTransformer
from sklearn.linear_model import LogisticRegression, LinearRegression
import statsmodels.api as sm
import statsmodels.formula.api as smf
Data Collection and Feature Engineering#
Read Dataset#
df = pd.read_csv("W106_purchases.txt", sep='\t', names=['consumer_id','purchase_amount', 'date_of_purchase'], parse_dates=['date_of_purchase'] )
df['year_of_purchase'] = df['date_of_purchase'].dt.year
max_date = df['date_of_purchase'].max() + dt.timedelta(days=1)
df['days_since'] = (max_date - df['date_of_purchase']).dt.days
df.head()
| consumer_id | purchase_amount | date_of_purchase | year_of_purchase | days_since | |
|---|---|---|---|---|---|
| 0 | 760 | 25.0 | 2009-11-06 | 2009 | 2247 |
| 1 | 860 | 50.0 | 2012-09-28 | 2012 | 1190 |
| 2 | 1200 | 100.0 | 2005-10-25 | 2005 | 3720 |
| 3 | 1420 | 50.0 | 2009-07-09 | 2009 | 2367 |
| 4 | 1940 | 70.0 | 2013-01-25 | 2013 | 1071 |
Generate Consumer_df Input and Target (Revenue_2015)#
def get_consumer_df(df, offset=0):
df = df.copy()
df = df[df['days_since']>offset]
consumer_df = df.groupby('consumer_id').agg(recency=('days_since', 'min'),
frequency=('date_of_purchase', 'count'),
# monetary=('purchase_amount', 'mean'),
avg_purchase_amount=('purchase_amount', 'mean'),
max_purchase_amount=('purchase_amount', 'max'),
first_purchase=('days_since', 'max'),
# revenue_till_date=('purchase_amount', 'sum'),
# first_purchase_date=('date_of_purchase', 'min'),
# first_purchase_year=('year_of_purchase', 'min'),
# last_purchase_date=('date_of_purchase', 'max'),
# last_purchase_year=('year_of_purchase', 'max'),
); consumer_df.head()
consumer_df['recency'] = consumer_df['recency'] - offset
consumer_df['first_purchase'] = consumer_df['first_purchase'] - offset
# consumer_df['segment'] = np.nan
# rec_filter = consumer_df['recency']
# first_purchase_filter = consumer_df['first_purchase']
# consumer_df.loc[(rec_filter <=365) & (consumer_df['monetary'] >= 100), 'segment'] = 'active high'
# consumer_df.loc[(rec_filter <=365) & (consumer_df['monetary'] < 100), 'segment'] = 'active low'""
# consumer_df.loc[(rec_filter <=365) & (first_purchase_filter <=365) & (consumer_df['monetary'] >= 100) , 'segment'] = 'new active high'
# consumer_df.loc[(rec_filter <=365) & (first_purchase_filter <=365) & (consumer_df['monetary'] < 100) , 'segment'] = 'new active low'
# consumer_df.loc[(rec_filter>365) & (rec_filter<=2*365) & (consumer_df['monetary'] >= 100), 'segment'] = 'warm high'
# consumer_df.loc[(rec_filter>365) & (rec_filter<=2*365) & (consumer_df['monetary'] < 100), 'segment'] = 'warm low'
# consumer_df.loc[(rec_filter>365) & (rec_filter<=2*365) & (first_purchase_filter <=2*365) & (consumer_df['monetary'] >= 100) , 'segment'] = 'new warm high'
# consumer_df.loc[(rec_filter>365) & (rec_filter<=2*365) & (first_purchase_filter <=2*365) & (consumer_df['monetary'] < 100) , 'segment'] = 'new warm low'
# consumer_df.loc[(rec_filter>2*365) & (rec_filter<=3*365), 'segment'] = 'cold'
# consumer_df.loc[(rec_filter>3*365), 'segment'] = 'inactive'
return consumer_df
revenue_df = df[df['year_of_purchase']==2015].groupby('consumer_id').agg(revenue_2015=('purchase_amount', 'sum')); revenue_df.head()
| revenue_2015 | |
|---|---|
| consumer_id | |
| 80 | 80.0 |
| 480 | 45.0 |
| 830 | 50.0 |
| 850 | 60.0 |
| 860 | 60.0 |
cons_df_2014 = get_consumer_df(df, offset=365); cons_df_2014.head()
| recency | frequency | avg_purchase_amount | max_purchase_amount | first_purchase | |
|---|---|---|---|---|---|
| consumer_id | |||||
| 10 | 3464 | 1 | 30.0 | 30.0 | 3464 |
| 80 | 302 | 6 | 70.0 | 80.0 | 3386 |
| 90 | 393 | 10 | 115.8 | 153.0 | 3418 |
| 120 | 1036 | 1 | 20.0 | 20.0 | 1036 |
| 130 | 2605 | 2 | 50.0 | 60.0 | 3345 |
Prepare Training dataset#
df_insample = pd.merge(cons_df_2014, revenue_df, left_index=True,right_index=True, how='left')
df_insample['active_2015'] = 1
df_insample.loc[df_insample.revenue_2015.isnull(), 'active_2015']=0
df_insample = df_insample.fillna(0)
df_insample.head()
| recency | frequency | avg_purchase_amount | max_purchase_amount | first_purchase | revenue_2015 | active_2015 | |
|---|---|---|---|---|---|---|---|
| consumer_id | |||||||
| 10 | 3464 | 1 | 30.0 | 30.0 | 3464 | 0.0 | 0 |
| 80 | 302 | 6 | 70.0 | 80.0 | 3386 | 80.0 | 1 |
| 90 | 393 | 10 | 115.8 | 153.0 | 3418 | 0.0 | 0 |
| 120 | 1036 | 1 | 20.0 | 20.0 | 1036 | 0.0 | 0 |
| 130 | 2605 | 2 | 50.0 | 60.0 | 3345 | 0.0 | 0 |
Prepare Out of Sample Dataset#
df_outsample = get_consumer_df(df, offset=0);df_outsample.shape
(18417, 5)
df_outsample.head()
| recency | frequency | avg_purchase_amount | max_purchase_amount | first_purchase | |
|---|---|---|---|---|---|
| consumer_id | |||||
| 10 | 3829 | 1 | 30.000000 | 30.0 | 3829 |
| 80 | 343 | 7 | 71.428571 | 80.0 | 3751 |
| 90 | 758 | 10 | 115.800000 | 153.0 | 3783 |
| 120 | 1401 | 1 | 20.000000 | 20.0 | 1401 |
| 130 | 2970 | 2 | 50.000000 | 60.0 | 3710 |
Predictive Models#
def process_df(df):
df_cp = df.copy()
df_cp['frequency'] = np.log1p(df_cp['frequency'])
df_cp['avg_purchase_amount'] = np.log1p(df_cp['avg_purchase_amount'])
return df_cp
Likelihood of Purchase#
df_insample.columns
Index(['recency', 'frequency', 'avg_purchase_amount', 'max_purchase_amount',
'first_purchase', 'revenue_2015', 'active_2015'],
dtype='object')
input_ds = df_insample[['recency', 'frequency', 'avg_purchase_amount', 'max_purchase_amount',
'first_purchase']]
y = df_insample['active_2015']
X = sm.add_constant(input_ds); X.head()
| const | recency | frequency | avg_purchase_amount | max_purchase_amount | first_purchase | |
|---|---|---|---|---|---|---|
| consumer_id | ||||||
| 10 | 1.0 | 3464 | 1 | 30.0 | 30.0 | 3464 |
| 80 | 1.0 | 302 | 6 | 70.0 | 80.0 | 3386 |
| 90 | 1.0 | 393 | 10 | 115.8 | 153.0 | 3418 |
| 120 | 1.0 | 1036 | 1 | 20.0 | 20.0 | 1036 |
| 130 | 1.0 | 2605 | 2 | 50.0 | 60.0 | 3345 |
model_purchase_incidence = sm.Logit(y, X).fit()
Optimization terminated successfully.
Current function value: 0.365836
Iterations 8
model_purchase_incidence.summary()
| Dep. Variable: | active_2015 | No. Observations: | 16905 |
|---|---|---|---|
| Model: | Logit | Df Residuals: | 16899 |
| Method: | MLE | Df Model: | 5 |
| Date: | Sat, 28 May 2022 | Pseudo R-squ.: | 0.3214 |
| Time: | 19:48:41 | Log-Likelihood: | -6184.5 |
| converged: | True | LL-Null: | -9113.9 |
| Covariance Type: | nonrobust | LLR p-value: | 0.000 |
| coef | std err | z | P>|z| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| const | -0.5331 | 0.044 | -12.087 | 0.000 | -0.620 | -0.447 |
| recency | -0.0020 | 6e-05 | -32.748 | 0.000 | -0.002 | -0.002 |
| frequency | 0.2195 | 0.015 | 14.840 | 0.000 | 0.191 | 0.249 |
| avg_purchase_amount | 0.0004 | 0.000 | 1.144 | 0.253 | -0.000 | 0.001 |
| max_purchase_amount | -0.0002 | 0.000 | -0.574 | 0.566 | -0.001 | 0.000 |
| first_purchase | -1.167e-05 | 3.93e-05 | -0.297 | 0.766 | -8.86e-05 | 6.53e-05 |
Amount of Purchase#
df_insample[df_insample['active_2015']==1]
| recency | frequency | avg_purchase_amount | max_purchase_amount | first_purchase | revenue_2015 | active_2015 | |
|---|---|---|---|---|---|---|---|
| consumer_id | |||||||
| 80 | 302 | 6 | 70.000000 | 80.0 | 3386 | 80.0 | 1 |
| 480 | 16 | 11 | 62.272727 | 235.0 | 3313 | 45.0 | 1 |
| 830 | 267 | 6 | 48.333333 | 60.0 | 3374 | 50.0 | 1 |
| 850 | 62 | 8 | 28.125000 | 30.0 | 3051 | 60.0 | 1 |
| 860 | 267 | 9 | 53.333333 | 60.0 | 3643 | 60.0 | 1 |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 234590 | 1 | 1 | 20.000000 | 20.0 | 1 | 25.0 | 1 |
| 234640 | 1 | 1 | 30.000000 | 30.0 | 1 | 45.0 | 1 |
| 234660 | 1 | 1 | 35.000000 | 35.0 | 1 | 40.0 | 1 |
| 234760 | 1 | 1 | 20.000000 | 20.0 | 1 | 15.0 | 1 |
| 236660 | 390 | 2 | 75.000000 | 100.0 | 684 | 100.0 | 1 |
3886 rows × 7 columns
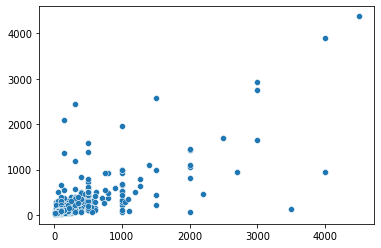
model_monetary_prediction = smf.ols(formula='revenue_2015 ~ avg_purchase_amount + max_purchase_amount', data=df_insample[df_insample['active_2015']==1])
res = model_monetary_prediction.fit()
res.summary()
| Dep. Variable: | revenue_2015 | R-squared: | 0.605 |
|---|---|---|---|
| Model: | OLS | Adj. R-squared: | 0.605 |
| Method: | Least Squares | F-statistic: | 2979. |
| Date: | Sat, 28 May 2022 | Prob (F-statistic): | 0.00 |
| Time: | 20:01:40 | Log-Likelihood: | -24621. |
| No. Observations: | 3886 | AIC: | 4.925e+04 |
| Df Residuals: | 3883 | BIC: | 4.927e+04 |
| Df Model: | 2 | ||
| Covariance Type: | nonrobust |
| coef | std err | t | P>|t| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| Intercept | 20.7471 | 2.381 | 8.713 | 0.000 | 16.079 | 25.415 |
| avg_purchase_amount | 0.6749 | 0.033 | 20.575 | 0.000 | 0.611 | 0.739 |
| max_purchase_amount | 0.2923 | 0.024 | 12.367 | 0.000 | 0.246 | 0.339 |
| Omnibus: | 5580.836 | Durbin-Watson: | 2.007 |
|---|---|---|---|
| Prob(Omnibus): | 0.000 | Jarque-Bera (JB): | 8162692.709 |
| Skew: | 7.843 | Prob(JB): | 0.00 |
| Kurtosis: | 226.980 | Cond. No. | 315. |
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
y = res.predict(df_insample[df_insample['active_2015']==1]).values
x = df_insample[df_insample['active_2015']==1]['revenue_2015'].values
sns.scatterplot(x,y)
/opt/anaconda/envs/aiking/lib/python3.9/site-packages/seaborn/_decorators.py:36: FutureWarning: Pass the following variables as keyword args: x, y. From version 0.12, the only valid positional argument will be `data`, and passing other arguments without an explicit keyword will result in an error or misinterpretation.
warnings.warn(
<AxesSubplot:>
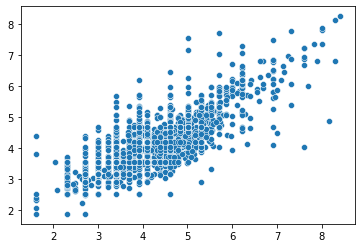
model_monetary_prediction2 = smf.ols(formula='np.log(revenue_2015) ~ np.log(avg_purchase_amount) + np.log(max_purchase_amount)', data=df_insample[df_insample['active_2015']==1])
res2 = model_monetary_prediction2.fit()
res2.summary()
| Dep. Variable: | np.log(revenue_2015) | R-squared: | 0.693 |
|---|---|---|---|
| Model: | OLS | Adj. R-squared: | 0.693 |
| Method: | Least Squares | F-statistic: | 4377. |
| Date: | Sat, 28 May 2022 | Prob (F-statistic): | 0.00 |
| Time: | 20:12:35 | Log-Likelihood: | -2644.6 |
| No. Observations: | 3886 | AIC: | 5295. |
| Df Residuals: | 3883 | BIC: | 5314. |
| Df Model: | 2 | ||
| Covariance Type: | nonrobust |
| coef | std err | t | P>|t| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| Intercept | 0.3700 | 0.040 | 9.242 | 0.000 | 0.292 | 0.448 |
| np.log(avg_purchase_amount) | 0.5488 | 0.042 | 13.171 | 0.000 | 0.467 | 0.631 |
| np.log(max_purchase_amount) | 0.3881 | 0.038 | 10.224 | 0.000 | 0.314 | 0.463 |
| Omnibus: | 501.505 | Durbin-Watson: | 1.961 |
|---|---|---|---|
| Prob(Omnibus): | 0.000 | Jarque-Bera (JB): | 3328.833 |
| Skew: | 0.421 | Prob(JB): | 0.00 |
| Kurtosis: | 7.455 | Cond. No. | 42.2 |
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
y = res2.predict(df_insample[df_insample['active_2015']==1]).values
x = np.log(df_insample[df_insample['active_2015']==1]['revenue_2015'].values)
sns.scatterplot(x,y)
/opt/anaconda/envs/aiking/lib/python3.9/site-packages/seaborn/_decorators.py:36: FutureWarning: Pass the following variables as keyword args: x, y. From version 0.12, the only valid positional argument will be `data`, and passing other arguments without an explicit keyword will result in an error or misinterpretation.
warnings.warn(
<AxesSubplot:>
Scoring and Out of Sample Prediction#
out = df_outsample.copy()
out['Prob']= model_purchase_incidence.predict(sm.add_constant(df_outsample.copy()))
out['Monetary'] = np.exp( res2.predict(df_outsample.copy()))
out['Score'] = out['Prob']*out['Monetary']
out.head()
| recency | frequency | avg_purchase_amount | max_purchase_amount | first_purchase | Prob | Monetary | Score | |
|---|---|---|---|---|---|---|---|---|
| consumer_id | ||||||||
| 10 | 3829 | 1 | 30.000000 | 30.0 | 3829 | 0.000380 | 35.048014 | 0.013326 |
| 80 | 343 | 7 | 71.428571 | 80.0 | 3751 | 0.575159 | 82.558085 | 47.484052 |
| 90 | 758 | 10 | 115.800000 | 153.0 | 3783 | 0.538104 | 138.426136 | 74.487670 |
| 120 | 1401 | 1 | 20.000000 | 20.0 | 1401 | 0.044037 | 23.970452 | 1.055597 |
| 130 | 2970 | 2 | 50.000000 | 60.0 | 3710 | 0.002568 | 60.709281 | 0.155924 |
out.describe().T
| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| recency | 18417.0 | 1253.037900 | 1081.437868 | 1.000000 | 244.000000 | 1070.000000 | 2130.000000 | 4014.000000 |
| frequency | 18417.0 | 2.782375 | 2.936888 | 1.000000 | 1.000000 | 2.000000 | 3.000000 | 45.000000 |
| avg_purchase_amount | 18417.0 | 57.792985 | 154.360109 | 5.000000 | 21.666667 | 30.000000 | 50.000000 | 4500.000000 |
| max_purchase_amount | 18417.0 | 68.756314 | 194.317960 | 5.000000 | 25.000000 | 30.000000 | 60.000000 | 4500.000000 |
| first_purchase | 18417.0 | 1984.009882 | 1133.405441 | 1.000000 | 988.000000 | 2087.000000 | 2992.000000 | 4016.000000 |
| Prob | 18417.0 | 0.224987 | 0.251136 | 0.000263 | 0.012637 | 0.106187 | 0.397817 | 0.999904 |
| Monetary | 18417.0 | 65.632173 | 147.887338 | 6.540053 | 28.999793 | 35.048014 | 57.298430 | 3832.952670 |
| Score | 18417.0 | 18.833654 | 70.211180 | 0.003298 | 0.455815 | 4.556268 | 17.957241 | 2854.156430 |
Note
Expected revenue for each customer based on score = 18.83