Topic Modelling using NMF and SVD
Contents
Topic Modelling using NMF and SVD#
Term Document Matrix#
Matrix Factorization
Bag of Words => no word order or sentence structure
Johnson-Lindenstrauss Lemma: (from wikipedia) a small set of points in a high-dimensional space can be embedded into a space of much lower dimension in such a way that distances between the points are nearly preserved.
It is desirable to be able to reduce dimensionality of data in a way that preserves relevant structure. The Johnson–Lindenstrauss lemma is a classic result of this type.
References#
Imports#
import numpy as np
import scipy as sp
import matplotlib.pyplot as plt
from matplotlib import rcParams, animation, rc
from sklearn import decomposition
import pandas as pd
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
from ipywidgets.widgets import interact
from IPython.display import HTML
from fastcore.all import *
%matplotlib inline
# %matplotlib notebook
np.set_printoptions(suppress=True)
categories = ['alt.atheism', 'talk.religion.misc', 'comp.graphics', 'sci.space']
remove = ('headers', 'footers', 'quotes')
newsgroups_train = fetch_20newsgroups(subset='train', categories=categories, remove=remove)
newsgroups_test = fetch_20newsgroups(subset='test', categories=categories, remove=remove)
newsgroups_test.keys()
dict_keys(['data', 'filenames', 'target_names', 'target', 'DESCR'])
for i in newsgroups_test.keys():
print(i, len(newsgroups_train[i]))
data 2034
filenames 2034
target_names 4
target 2034
DESCR 10617
# newsgroups_train['target_names']
newsgroups_train.target_names
['alt.atheism', 'comp.graphics', 'sci.space', 'talk.religion.misc']
np.unique(newsgroups_train['target'])
array([0, 1, 2, 3])
newsgroups_train.target_names
['alt.atheism', 'comp.graphics', 'sci.space', 'talk.religion.misc']
num_topics, num_top_words = 6, 8
vectorizer = CountVectorizer(stop_words='english')
vectorizer
CountVectorizer(stop_words='english')
vectors = vectorizer.fit_transform(newsgroups_train.data).todense()
vectors.shape
(2034, 26576)
vocab = np.array(vectorizer.get_feature_names())
vocab.shape
/opt/anaconda/envs/aiking/lib/python3.9/site-packages/sklearn/utils/deprecation.py:87: FutureWarning: Function get_feature_names is deprecated; get_feature_names is deprecated in 1.0 and will be removed in 1.2. Please use get_feature_names_out instead.
warnings.warn(msg, category=FutureWarning)
(26576,)
vocab[7000:7020]
array(['cosmonauts', 'cosmos', 'cosponsored', 'cost', 'costa', 'costar',
'costing', 'costly', 'costruction', 'costs', 'cosy', 'cote',
'couched', 'couldn', 'council', 'councils', 'counsel',
'counselees', 'counselor', 'count'], dtype='<U80')
SVD#
Good words to separate topics - word which appear frequently in one topic doesn’t appear that frequently in other topic => Topics are orthogonal
SVD
Matrix = Orthogonal rows (Embedding of # by the words they cooccur with) + diagnoal rows( relative importance of each factor) + orthogonal columns ( embedding of words by # they cooccure with
Exact Decomposition
Applications
Semanic Analysis
Collaborative filtering/ recommendations
Moore-Penrose pseudoinverse
Data Compression
Principal Component Analysis
%time U, s, Vh = sp.linalg.svd(vectors, full_matrices=False)
CPU times: user 1min 35s, sys: 9.72 s, total: 1min 44s
Wall time: 28 s
U.shape, s.shape, Vh.shape
((2034, 2034), (2034,), (2034, 26576))
(U@Vh).shape
(2034, 26576)
U@U.T
array([[ 1., -0., 0., ..., 0., 0., 0.],
[-0., 1., 0., ..., 0., -0., 0.],
[ 0., 0., 1., ..., 0., -0., 0.],
...,
[ 0., 0., 0., ..., 1., -0., 0.],
[ 0., -0., -0., ..., -0., 1., 0.],
[ 0., 0., 0., ..., 0., 0., 1.]])
Vh@Vh.T
array([[ 1., 0., -0., ..., -0., 0., 0.],
[ 0., 1., -0., ..., -0., -0., 0.],
[-0., -0., 1., ..., -0., -0., -0.],
...,
[-0., -0., -0., ..., 1., -0., -0.],
[ 0., -0., -0., ..., -0., 1., -0.],
[ 0., 0., -0., ..., -0., -0., 1.]])
plt.plot(s)
[<matplotlib.lines.Line2D at 0xaee5b6b9f70>]
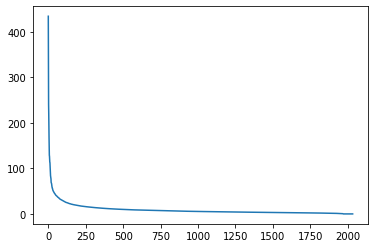
# @interact(i=(1,s.shape[0]))
@interact(i=(1,20))
def plot_features(i=20):
plt.plot(s[:i])
num_topics, num_top_words = 6, 8
def show_topics(v_mat,vocab,n_docs=10, n_top_words=8):
v_docs = v_mat[:n_docs]
return [" ".join(gw) for gw in vocab[np.argsort(v_docs)[:,-(n_top_words+1):-1]]]
n_docs = 10
n_top_words=8
v_docs = Vh[:n_docs]
v_docs.shape
v_docs
array([[-0.00940972, -0.0114532 , -0.00002169, ..., -0.00000572,
-0.00001144, -0.00109243],
[-0.00356688, -0.01769167, -0.00003045, ..., -0.00000773,
-0.00001546, -0.0018549 ],
[ 0.00094971, -0.02282845, -0.00002339, ..., -0.0000122 ,
-0.0000244 , 0.00150538],
...,
[-0.00218087, -0.04322025, -0.00012552, ..., 0.00003759,
0.00007518, 0.00160907],
[-0.00039196, 0.00494894, 0.00000309, ..., -0.00001321,
-0.00002643, -0.00015038],
[ 0.00306552, -0.01437264, -0.00000405, ..., -0.00003597,
-0.00007193, 0.00056218]])
# vocab[np.argsort(v_docs)[0,:][-(n_top_words+1):-1]]
np.argsort(v_docs[0,:])
array([13816, 12642, 8956, ..., 19210, 7181, 8462])
show_topics(Vh, vocab)
['salvadorans imaginative surreal kindergarten galacticentric surname propagandist critus',
'bit format jfif image quality color file gif',
'send ftp ray 3d 128 mail pub edu',
'religious graphics does atheism atheists people matthew god',
'tool display tools available software analysis processing data',
'atheist true argument religion believe religious atheism atheists',
'surface probes missions moon probe mars lunar nasa',
'mariner orbit moon probes mars lunar surface probe',
'false premises argumentum ad true example conclusion fallacy',
'star material nasa physical universe theory image larson']
Note
We have many tools that allow us to filter matrix exactly.
Non-negative Matrix Factorization(NMF)#
NMF - constraining factors to be non-negative instead of orthogonal.
World is inherently non negative.
Applications
Face Decompositions
Collaborative Filtering / Movie Recommendation
Audio Source Seperation
Chemistry
Bioinformatics
Topic Modelling
m, n = vectors.shape # documents, words
m, n
(2034, 26576)
d = 5 # num of topics
clf = decomposition.NMF(n_components=d, random_state=1)
clf
NMF(n_components=5, random_state=1)
vectors.shape
(2034, 26576)
W1 = clf.fit_transform(vectors)
W1
/opt/anaconda/envs/aiking/lib/python3.9/site-packages/sklearn/utils/validation.py:585: FutureWarning: np.matrix usage is deprecated in 1.0 and will raise a TypeError in 1.2. Please convert to a numpy array with np.asarray. For more information see: https://numpy.org/doc/stable/reference/generated/numpy.matrix.html
warnings.warn(
/opt/anaconda/envs/aiking/lib/python3.9/site-packages/sklearn/decomposition/_nmf.py:289: FutureWarning: The 'init' value, when 'init=None' and n_components is less than n_samples and n_features, will be changed from 'nndsvd' to 'nndsvda' in 1.1 (renaming of 0.26).
warnings.warn(
array([[0.08858936, 0.02984714, 0. , 0.04220515, 0. ],
[0. , 0.00074146, 0.0037713 , 0.02133068, 0.00096886],
[0. , 0.01650813, 0.00026615, 0.02582674, 0.00294897],
...,
[0.00897787, 0.03011237, 0.0033981 , 0.01453643, 0.00331353],
[0.01862327, 0. , 0.00123129, 0.21812662, 0. ],
[0. , 0. , 0. , 0. , 0. ]])
W1.shape
(2034, 5)
H1 = clf.components_
H1
array([[0.12126083, 0. , 0. , ..., 0.00003202, 0.00006403,
0.00028996],
[0.11928575, 0.12085267, 0.00016592, ..., 0.0001165 , 0.000233 ,
0.05186412],
[0.05766391, 0.48160644, 0.0007993 , ..., 0.00028762, 0.00057525,
0. ],
[0. , 0.14794335, 0. , ..., 0.00006585, 0.0001317 ,
0. ],
[0.12742192, 0.19356417, 0.00050472, ..., 0. , 0. ,
0. ]])
H1.shape
(5, 26576)
show_topics(H1, vocab)
['version quality format images color file gif image',
'3d send ftp ray 128 mail pub graphics',
'data market year satellites commercial nasa satellite launch',
'just said atheism does atheists matthew people god',
'images analysis edu ftp processing software available data']
TFIDF#
Topic Frequency-Inverse Document Frequency (TF-IDF) is a way to normalize term counts by taking into account how often they appear in a document, how long the document is, and how commmon/rare the term is.
TF = (# occurrences of term t in document) / (# of words in documents)
IDF = log(# of documents / # documents with term t in it)
Example: Consider a document containing 100 words wherein the word cat appears 3 times. The term frequency (i.e., tf) for cat is then (3 / 100) = 0.03. Now, assume we have 10 million documents and the word cat appears in one thousand of these. Then, the inverse document frequency (i.e., idf) is calculated as log(10,000,000 / 1,000) = 4. Thus, the Tf-idf weight is the product of these quantities: 0.03 * 4 = 0.12
vectorizer = TfidfVectorizer(stop_words="english")
vectorizer.fit_transform?
Signature: vectorizer.fit_transform(raw_documents, y=None)
Docstring:
Learn vocabulary and idf, return document-term matrix.
This is equivalent to fit followed by transform, but more efficiently
implemented.
Parameters
----------
raw_documents : iterable
An iterable which generates either str, unicode or file objects.
y : None
This parameter is ignored.
Returns
-------
X : sparse matrix of (n_samples, n_features)
Tf-idf-weighted document-term matrix.
File: /opt/anaconda/envs/aiking/lib/python3.9/site-packages/sklearn/feature_extraction/text.py
Type: method
vectors = vectorizer.fit_transform(newsgroups_train.data).todense(); vectors
matrix([[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]])
W1 = clf.fit_transform(vectors)
/opt/anaconda/envs/aiking/lib/python3.9/site-packages/sklearn/utils/validation.py:585: FutureWarning: np.matrix usage is deprecated in 1.0 and will raise a TypeError in 1.2. Please convert to a numpy array with np.asarray. For more information see: https://numpy.org/doc/stable/reference/generated/numpy.matrix.html
warnings.warn(
/opt/anaconda/envs/aiking/lib/python3.9/site-packages/sklearn/decomposition/_nmf.py:289: FutureWarning: The 'init' value, when 'init=None' and n_components is less than n_samples and n_features, will be changed from 'nndsvd' to 'nndsvda' in 1.1 (renaming of 0.26).
warnings.warn(
clf.components_.shape
(5, 26576)
H1 = clf.components_
vocab = np.array(vectorizer.get_feature_names())
vocab.shape
vocab
/opt/anaconda/envs/aiking/lib/python3.9/site-packages/sklearn/utils/deprecation.py:87: FutureWarning: Function get_feature_names is deprecated; get_feature_names is deprecated in 1.0 and will be removed in 1.2. Please use get_feature_names_out instead.
warnings.warn(msg, category=FutureWarning)
array(['00', '000', '0000', ..., 'zware', 'zwarte', 'zyxel'], dtype='<U80')
show_topics(H1, vocab)
['know morality say objective like just think don',
'format know windows program file image files thanks',
'station earth lunar moon orbit shuttle launch nasa',
'vice queens sank manhattan bronx beauchaine tek bobbe',
'faith belief does atheism christian believe bible jesus']
vocab[7000:7020]
array(['cosmonauts', 'cosmos', 'cosponsored', 'cost', 'costa', 'costar',
'costing', 'costly', 'costruction', 'costs', 'cosy', 'cote',
'couched', 'couldn', 'council', 'councils', 'counsel',
'counselees', 'counselor', 'count'], dtype='<U80')
plt.plot(clf.components_[0])
[<matplotlib.lines.Line2D at 0xaee5b12b250>]
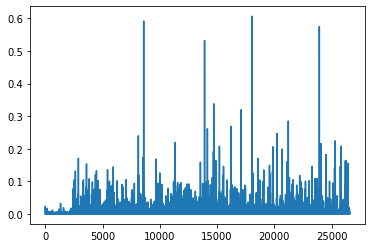
clf.reconstruction_err_
43.71292605795258
NMF in summary#
Benefit fast and easy to use
Took years of research to master
For NMF, matrix need to be as tall as wide - otherwise we will have error in fit_transform (\(m \ge n\) for matrix \(V^{mxn}\))
Can use df_min in CountVectorizer to only look at words that were in at least k of the split texts
Gradient Descent#
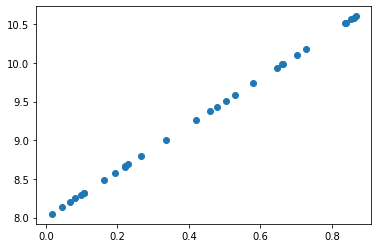
def lin(a, b, x): return a*x+b
a=3
b=8
n=30
x = np.random.random(n)
plt.scatter(x, lin(a, b, x))
y = lin(a, b, x)
y
array([ 8.66536449, 8.79541699, 10.56126547, 8.24715391, 10.51300969,
9.43275675, 8.04751459, 8.29722369, 10.10790904, 9.93738814,
8.31807423, 9.26202454, 8.13544973, 10.5840327 , 9.73784168,
9.98504435, 8.1977378 , 9.50929408, 10.18216117, 8.48690698,
8.66043837, 8.57549578, 10.60328607, 9.00900207, 9.9869936 ,
8.31974839, 10.52028891, 9.37556759, 8.68929477, 9.58876118])
def sse(y, y_pred) : return ((y-y_pred)**2).sum()
def loss(y, a, b, x): return sse(y, lin(a, b, x))
def avg_loss(y, a, b, x):
n = x.shape[0]
return np.sqrt(loss(y, a, b, x)/n)
avg_loss(y, a, b, x)
0.0
a_guess=-1.
b_guess=1.
avg_loss(y, a_guess, b_guess, x)
8.7778840202002
lr = 0.01; lr
# d[(y-(a*x+b))**2,b] = 2*(y-(a+bx))*(-1) = 2*(y_pred - y)
# d[(y-(a*x+b))**2,a] = 2 x (b + a x - y) = x * dy/db
0.01
a_guess=-1.
b_guess=-1.
def upd():
global a_guess, b_guess
y_pred = lin(a_guess, b_guess, x)
dydb = 2*(y_pred - y)
dyda = x*dydb
a_guess -= lr*dyda.mean()
b_guess -= lr*dydb.mean()
fig = plt.figure(dpi=100, figsize=(5, 4))
plt.scatter(x,y)
line, = plt.plot(x,lin(a_guess,b_guess,x))
plt.close()
def animate(i):
line.set_ydata(lin(a_guess, b_guess, x))
for i in range(10): upd()
return line,
ani = animation.FuncAnimation(fig, animate, np.arange(0, 40), interval=100)
plt.show()
HTML(ani.to_html5_video())
Numpy NMF Implementation#
vectors.shape
(2034, 26576)
m, n = vectors.shape
d = 5 #num of topics
# W = np.random.randn?
# W = np.random.randn
W = np.abs(np.random.randn(m, d))
H = np.abs(np.random.randn(d,n))
W.shape, H.shape
((2034, 5), (5, 26576))
V = vectors
V.shape
(2034, 26576)
np.sum(np.eye(3)*2)
np.trace(np.eye(3))
3.0
np.diag(np.eye(3))
array([1., 1., 1.])
# Frobenius norm
# np.sum(np.abs(V-W@H))
def frobenius(R): return np.sqrt(np.trace(R@R.T))
def grads(V, W, H, lam=1e3, mu=1e-6):
R = W@H - V
return R@H.T + penalty(W,mu)*lam, \
W.T@R+penalty(H,mu)*lam
def penalty(V, mu=1e-6):
return np.where(V>=mu, 0, np.min(V-mu, 0))
def upd(V, W, H, lr=1e-2):
dW, dH = grads(V,W,H)
W -=lr*dW; H -=lr*dH
def report(V, W, H):
R = V-W@H
print(#frobenius(R),
np.linalg.norm(R),
W.min(), H.min(),
(W<0).sum(), (H<0).sum())
R = V-W@H
frobenius(R)
report(V, W, H)
26304.31003242264 8.189374727876224e-05 2.087590827597957e-06 0 0
T=np.random.randn(2,2);T
array([[-1.43858379, -0.7124614 ],
[ 1.6209956 , -0.1244286 ]])
penalty(T)*1e3
array([[-1438.58479296, -712.46239837],
[ 0. , -712.46239837]])
1e-2
0.01
T.min()
-1.4385837929618248
upd(V,W,H)
report(V, W, H)
1684343703.54675 -1864.8739728368212 -152.72994046790748 10170 132880
W = np.abs(np.random.normal(scale=0.01, size=(m,d)))
H = np.abs(np.random.normal(scale=0.01, size=(d,n)))
report(V, W, H)
44.42709338245277 2.0082546532603725e-06 2.5518343448689233e-07 0 0
%%time
upd(V,W,H)
report(V,W,H)
44.41913949000226 -0.001166507815926114 -7.840976535951406e-05 156 280
CPU times: user 1.61 s, sys: 1.78 s, total: 3.38 s
Wall time: 1.06 s
%%time
for i in range(50):
upd(V,W,H)
if i % 10 == 0 : report(V,W,H)
44.413605139935 -0.0007657338245319698 -7.283834887410182e-05 124 295
44.3753063735921 -0.0003872330392145567 -4.58065321347774e-05 38 514
44.34679042913337 -0.00023315718246128998 -6.448792691161058e-05 30 977
44.315143320648524 -0.0001187202450460459 -0.00011718420987392124 28 1549
44.28030523243511 -0.00014848956987308697 -0.00012402489019729026 32 2224
CPU times: user 59.8 s, sys: 48.7 s, total: 1min 48s
Wall time: 32.9 s
show_topics(H, vocab)
['does like just know think don god space',
'does think know god like just people space',
'know does think like just don space people',
'does think know like people god don just',
'good know just like don people think space']
Pytorch Implementation#
import torch
import torch.cuda as tc
from torch.autograd import Variable
def V(M): return Variable(M, requires_grad=True)
vectors = vectorizer.fit_transform(newsgroups_train.data).todense(); vectors
matrix([[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]])
v = vectors.copy()
v
matrix([[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]])
t_vectors = torch.Tensor(v.astype(np.float32)).cuda()
t_vectors
tensor([[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]], device='cuda:0')
def grads_t(M, W, H, lam=1e2, mu=1e-5):
R = W.mm(H)-M
return (R.mm(H.t())) + penalty_t(W,mu)*lam,\
W.t().mm(R) + penalty_t(H,mu)*lam
# (W.t().mm(R)) +penalty_t(H,mu)*lam
def penalty_t(M, mu=1e-5):
return (M<mu).type(tc.FloatTensor)\
*torch.clamp(M-mu, max=0.)
# return np.where(V>=mu, 0, np.min(V-mu, 0))
def upd_t(M, W, H, lr=1e-2):
dW, dH = grads_t(M,W,H)
W.sub_(lr*dW); H.sub_(lr*dH)
def report_t(M, W, H):
R = M-W.mm(H)
print(#frobenius(R),
R.norm(2),
W.min(), H.min(),
(W<0).sum(), (H<0).sum())
m, n = v.shape
d = 6
t_W = tc.FloatTensor(m, d)
t_H = tc.FloatTensor(d, n)
t_W.normal_(std=0.01).abs_();
t_H.normal_(std=0.01).abs_();
t_W.shape, t_H.shape
(torch.Size([2034, 6]), torch.Size([6, 26576]))
lr = 0.05
for i in range(1000):
upd_t(t_vectors, t_W, t_H, lr)
if i%100 == 0:
report_t(t_vectors, t_W, t_H)
lr *= 0.9
tensor(44.3929, device='cuda:0') tensor(-0.0065, device='cuda:0') tensor(-0.0005, device='cuda:0') tensor(1579, device='cuda:0') tensor(2166, device='cuda:0')
tensor(43.7250, device='cuda:0') tensor(-0.0070, device='cuda:0') tensor(-0.0132, device='cuda:0') tensor(2066, device='cuda:0') tensor(21653, device='cuda:0')
tensor(43.7064, device='cuda:0') tensor(-0.0061, device='cuda:0') tensor(-0.0116, device='cuda:0') tensor(2179, device='cuda:0') tensor(24659, device='cuda:0')
tensor(43.6964, device='cuda:0') tensor(-0.0086, device='cuda:0') tensor(-0.0084, device='cuda:0') tensor(2396, device='cuda:0') tensor(25231, device='cuda:0')
tensor(43.6673, device='cuda:0') tensor(-0.0049, device='cuda:0') tensor(-0.0051, device='cuda:0') tensor(2482, device='cuda:0') tensor(24241, device='cuda:0')
tensor(43.6627, device='cuda:0') tensor(-0.0043, device='cuda:0') tensor(-0.0045, device='cuda:0') tensor(3044, device='cuda:0') tensor(25558, device='cuda:0')
tensor(43.6616, device='cuda:0') tensor(-0.0050, device='cuda:0') tensor(-0.0038, device='cuda:0') tensor(3151, device='cuda:0') tensor(26004, device='cuda:0')
tensor(43.6601, device='cuda:0') tensor(-0.0047, device='cuda:0') tensor(-0.0044, device='cuda:0') tensor(2952, device='cuda:0') tensor(26325, device='cuda:0')
tensor(43.6583, device='cuda:0') tensor(-0.0041, device='cuda:0') tensor(-0.0042, device='cuda:0') tensor(2852, device='cuda:0') tensor(26202, device='cuda:0')
tensor(43.6558, device='cuda:0') tensor(-0.0050, device='cuda:0') tensor(-0.0040, device='cuda:0') tensor(3208, device='cuda:0') tensor(28970, device='cuda:0')
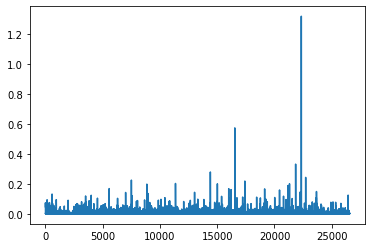
show_topics(t_H.cpu().numpy(), vocab)
['sci gov orbit data station launch shuttle nasa',
'real ve know time people think like don',
'christians belief does atheism christian believe bible jesus',
'know format windows program file image files graphics',
'don does religion values think people moral morality',
'vice queens sank manhattan beauchaine bronx tek bobbe']
plt.plot(t_H.cpu().numpy()[0])
[<matplotlib.lines.Line2D at 0xdd9826a2a90>]
Python Autograd#
Autograd Intro#
x = Variable(torch.ones(2,2), requires_grad=True)
x
tensor([[1., 1.],
[1., 1.]], requires_grad=True)
print(x)
tensor([[1., 1.],
[1., 1.]], requires_grad=True)
print(x.data)
tensor([[1., 1.],
[1., 1.]])
print(x.grad)
None
y = x+2
print(y)
tensor([[3., 3.],
[3., 3.]], grad_fn=<AddBackward0>)
z = y*y*3
out = z.sum()
print(z, out)
tensor([[27., 27.],
[27., 27.]], grad_fn=<MulBackward0>) tensor(108., grad_fn=<SumBackward0>)
out.backward()
print(x.grad)
tensor([[18., 18.],
[18., 18.]])
NMF with Autograd#
lam = 1e-6
m, n = vectors.shape
d = 6 # num of topics
pW = Variable(tc.FloatTensor(m,d), requires_grad=True)
pH = Variable(tc.FloatTensor(d,n), requires_grad=True)
pW
tensor([[ 9.5471e-09, -4.3698e-07, -3.2861e-06, 9.2815e-07, 8.1901e-08,
-4.0887e-07],
[-1.3723e-07, -1.4769e-05, 9.6822e-06, 5.6049e-08, 2.2556e-05,
4.2913e-08],
[-9.5589e-07, -7.9720e-06, 1.0199e-07, 1.3454e-06, 1.5050e-05,
8.0139e-07],
...,
[-3.3975e-07, 1.7489e-05, 4.3336e-08, -5.0231e-06, -3.6682e-07,
-3.6701e-07],
[ 1.4516e-07, -5.8843e-05, -4.0165e-05, -6.0871e-08, 8.3824e-05,
-1.0180e-06],
[ 5.1754e-11, 1.0262e-10, 9.8942e-12, -4.1353e-11, -3.6190e-10,
-1.0846e-11]], device='cuda:0', requires_grad=True)
pW.data.normal_(std=0.01).abs_()
pH.data.normal_(std=0.01).abs_()
pW
tensor([[0.0004, 0.0047, 0.0057, 0.0086, 0.0132, 0.0113],
[0.0095, 0.0050, 0.0014, 0.0197, 0.0099, 0.0050],
[0.0082, 0.0080, 0.0024, 0.0041, 0.0083, 0.0057],
...,
[0.0051, 0.0159, 0.0061, 0.0081, 0.0110, 0.0224],
[0.0148, 0.0090, 0.0080, 0.0089, 0.0073, 0.0135],
[0.0046, 0.0009, 0.0085, 0.0034, 0.0006, 0.0071]], device='cuda:0',
requires_grad=True)
t_vectors = torch.Tensor(v.astype(np.float32)).cuda()
t_vectors
tensor([[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]], device='cuda:0')
def report():
W, H = pW.data, pH.data
print((M-pW.mm(pH)).norm(2).data,
W.min(), H.min(),
(W<0).sum(), (H<0).sum())
def penalty(A):
return torch.pow((A<0).type(tc.FloatTensor)*torch.clamp(A, max=0), 2)
def penalize():
return penalty(pW).mean() + penalty(pH).mean()
def loss():
return (M -pW.mm(pH)).norm(2)+penalize()*lam
M = Variable(t_vectors).cuda()
M
tensor([[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]], device='cuda:0')
help(torch.optim.Adam)
Help on class Adam in module torch.optim.adam:
class Adam(torch.optim.optimizer.Optimizer)
| Adam(params, lr=0.001, betas=(0.9, 0.999), eps=1e-08, weight_decay=0, amsgrad=False)
|
| Implements Adam algorithm.
|
| .. math::
| \begin{aligned}
| &\rule{110mm}{0.4pt} \\
| &\textbf{input} : \gamma \text{ (lr)}, \beta_1, \beta_2
| \text{ (betas)},\theta_0 \text{ (params)},f(\theta) \text{ (objective)} \\
| &\hspace{13mm} \lambda \text{ (weight decay)}, \: amsgrad \\
| &\textbf{initialize} : m_0 \leftarrow 0 \text{ ( first moment)},
| v_0\leftarrow 0 \text{ (second moment)},\: \widehat{v_0}^{max}\leftarrow 0\\[-1.ex]
| &\rule{110mm}{0.4pt} \\
| &\textbf{for} \: t=1 \: \textbf{to} \: \ldots \: \textbf{do} \\
| &\hspace{5mm}g_t \leftarrow \nabla_{\theta} f_t (\theta_{t-1}) \\
| &\hspace{5mm}\textbf{if} \: \lambda \neq 0 \\
| &\hspace{10mm} g_t \leftarrow g_t + \lambda \theta_{t-1} \\
| &\hspace{5mm}m_t \leftarrow \beta_1 m_{t-1} + (1 - \beta_1) g_t \\
| &\hspace{5mm}v_t \leftarrow \beta_2 v_{t-1} + (1-\beta_2) g^2_t \\
| &\hspace{5mm}\widehat{m_t} \leftarrow m_t/\big(1-\beta_1^t \big) \\
| &\hspace{5mm}\widehat{v_t} \leftarrow v_t/\big(1-\beta_2^t \big) \\
| &\hspace{5mm}\textbf{if} \: amsgrad \\
| &\hspace{10mm}\widehat{v_t}^{max} \leftarrow \mathrm{max}(\widehat{v_t}^{max},
| \widehat{v_t}) \\
| &\hspace{10mm}\theta_t \leftarrow \theta_{t-1} - \gamma \widehat{m_t}/
| \big(\sqrt{\widehat{v_t}^{max}} + \epsilon \big) \\
| &\hspace{5mm}\textbf{else} \\
| &\hspace{10mm}\theta_t \leftarrow \theta_{t-1} - \gamma \widehat{m_t}/
| \big(\sqrt{\widehat{v_t}} + \epsilon \big) \\
| &\rule{110mm}{0.4pt} \\[-1.ex]
| &\bf{return} \: \theta_t \\[-1.ex]
| &\rule{110mm}{0.4pt} \\[-1.ex]
| \end{aligned}
|
| For further details regarding the algorithm we refer to `Adam: A Method for Stochastic Optimization`_.
|
| Args:
| params (iterable): iterable of parameters to optimize or dicts defining
| parameter groups
| lr (float, optional): learning rate (default: 1e-3)
| betas (Tuple[float, float], optional): coefficients used for computing
| running averages of gradient and its square (default: (0.9, 0.999))
| eps (float, optional): term added to the denominator to improve
| numerical stability (default: 1e-8)
| weight_decay (float, optional): weight decay (L2 penalty) (default: 0)
| amsgrad (boolean, optional): whether to use the AMSGrad variant of this
| algorithm from the paper `On the Convergence of Adam and Beyond`_
| (default: False)
|
| .. _Adam\: A Method for Stochastic Optimization:
| https://arxiv.org/abs/1412.6980
| .. _On the Convergence of Adam and Beyond:
| https://openreview.net/forum?id=ryQu7f-RZ
|
| Method resolution order:
| Adam
| torch.optim.optimizer.Optimizer
| builtins.object
|
| Methods defined here:
|
| __init__(self, params, lr=0.001, betas=(0.9, 0.999), eps=1e-08, weight_decay=0, amsgrad=False)
| Initialize self. See help(type(self)) for accurate signature.
|
| __setstate__(self, state)
|
| step(self, closure=None)
| Performs a single optimization step.
|
| Args:
| closure (callable, optional): A closure that reevaluates the model
| and returns the loss.
|
| ----------------------------------------------------------------------
| Methods inherited from torch.optim.optimizer.Optimizer:
|
| __getstate__(self)
|
| __repr__(self)
| Return repr(self).
|
| add_param_group(self, param_group)
| Add a param group to the :class:`Optimizer` s `param_groups`.
|
| This can be useful when fine tuning a pre-trained network as frozen layers can be made
| trainable and added to the :class:`Optimizer` as training progresses.
|
| Args:
| param_group (dict): Specifies what Tensors should be optimized along with group
| specific optimization options.
|
| load_state_dict(self, state_dict)
| Loads the optimizer state.
|
| Args:
| state_dict (dict): optimizer state. Should be an object returned
| from a call to :meth:`state_dict`.
|
| state_dict(self)
| Returns the state of the optimizer as a :class:`dict`.
|
| It contains two entries:
|
| * state - a dict holding current optimization state. Its content
| differs between optimizer classes.
| * param_groups - a list containing all parameter groups where each
| parameter group is a dict
|
| zero_grad(self, set_to_none: bool = False)
| Sets the gradients of all optimized :class:`torch.Tensor` s to zero.
|
| Args:
| set_to_none (bool): instead of setting to zero, set the grads to None.
| This will in general have lower memory footprint, and can modestly improve performance.
| However, it changes certain behaviors. For example:
| 1. When the user tries to access a gradient and perform manual ops on it,
| a None attribute or a Tensor full of 0s will behave differently.
| 2. If the user requests ``zero_grad(set_to_none=True)`` followed by a backward pass, ``.grad``\ s
| are guaranteed to be None for params that did not receive a gradient.
| 3. ``torch.optim`` optimizers have a different behavior if the gradient is 0 or None
| (in one case it does the step with a gradient of 0 and in the other it skips
| the step altogether).
|
| ----------------------------------------------------------------------
| Data descriptors inherited from torch.optim.optimizer.Optimizer:
|
| __dict__
| dictionary for instance variables (if defined)
|
| __weakref__
| list of weak references to the object (if defined)
# (torch.optim.Adam/
opt = torch.optim.Adam([pW,pH], lr=1e-3, betas=(0.9,0.9))
lr=0.05
report()
tensor(44.4393, device='cuda:0') tensor(7.9982e-07, device='cuda:0') tensor(2.1715e-08, device='cuda:0') tensor(0, device='cuda:0') tensor(0, device='cuda:0')
for i in range(1000):
opt.zero_grad()
l = loss()
l.backward()
opt.step()
if i % 100 ==99:
report()
lr *= 0.9
tensor(43.8757, device='cuda:0') tensor(-0.0856, device='cuda:0') tensor(-0.0843, device='cuda:0') tensor(3068, device='cuda:0') tensor(62686, device='cuda:0')
tensor(43.6954, device='cuda:0') tensor(-0.1680, device='cuda:0') tensor(-0.1618, device='cuda:0') tensor(3800, device='cuda:0') tensor(49265, device='cuda:0')
tensor(43.6364, device='cuda:0') tensor(-0.2488, device='cuda:0') tensor(-0.2549, device='cuda:0') tensor(3845, device='cuda:0') tensor(46335, device='cuda:0')
tensor(43.6285, device='cuda:0') tensor(-0.2613, device='cuda:0') tensor(-0.2972, device='cuda:0') tensor(3631, device='cuda:0') tensor(49044, device='cuda:0')
tensor(43.6285, device='cuda:0') tensor(-0.2609, device='cuda:0') tensor(-0.2967, device='cuda:0') tensor(3660, device='cuda:0') tensor(49023, device='cuda:0')
tensor(43.6285, device='cuda:0') tensor(-0.2608, device='cuda:0') tensor(-0.2964, device='cuda:0') tensor(3643, device='cuda:0') tensor(49037, device='cuda:0')
tensor(43.6285, device='cuda:0') tensor(-0.2608, device='cuda:0') tensor(-0.2963, device='cuda:0') tensor(3677, device='cuda:0') tensor(49003, device='cuda:0')
tensor(43.6285, device='cuda:0') tensor(-0.2606, device='cuda:0') tensor(-0.2962, device='cuda:0') tensor(3651, device='cuda:0') tensor(49054, device='cuda:0')
tensor(43.6285, device='cuda:0') tensor(-0.2606, device='cuda:0') tensor(-0.2960, device='cuda:0') tensor(3668, device='cuda:0') tensor(49392, device='cuda:0')
tensor(43.6285, device='cuda:0') tensor(-0.2604, device='cuda:0') tensor(-0.2960, device='cuda:0') tensor(3663, device='cuda:0') tensor(49160, device='cuda:0')
h = pH.data.cpu().numpy()
show_topics(h, vocab)
['does say moral just don morality people think',
'manhattan beauchaine bronx morality tek bobbe ico god',
'know space said graphics people think like don',
'launch shuttle people bible believe jesus nasa god',
'file does image know files jesus graphics thanks',
'morality data files thanks image program nasa objective']
plt.plot(h[0]);
Truncated SVD#
Big Matrices
Missing / Inaccurate Data - why spend compute resources when impression of input limits precision of output
Data transfer is often bottleneck - Algorithms with fewer passes are faster ( even if they require more floating point operations / flops)
GPU advantage
Full SVD vs Randomized SVD#
Randomized often inherently stable
performance guarantees do not depend on subtle spectral properties
Matrix-vector products can be done in parallel
vectors = vectorizer.fit_transform(newsgroups_train.data); vectors
<2034x26576 sparse matrix of type '<class 'numpy.float64'>'
with 133634 stored elements in Compressed Sparse Row format>
vectors.shape
(2034, 26576)
%time U, s, Vh = sp.linalg.svd(vectors.todense(), full_matrices=True)
CPU times: user 14min 28s, sys: 19.3 s, total: 14min 48s
Wall time: 3min 47s
%time U, s, Vh = sp.linalg.svd(vectors.todense(), full_matrices=False)
CPU times: user 1min 32s, sys: 7.18 s, total: 1min 39s
Wall time: 26 s
print(U.shape, s.shape, Vh.shape)
(2034, 2034) (2034,) (2034, 26576)
%time u, s, v = decomposition.randomized_svd(vectors, 5, random_state=23)
CPU times: user 282 ms, sys: 229 ms, total: 511 ms
Wall time: 131 ms
print(U.shape, s.shape, Vh.shape)
(2034, 2034) (5,) (2034, 26576)
%time u, s, v = decomposition.randomized_svd(vectors.todense(), 5, random_state=23)
CPU times: user 10.7 s, sys: 3.66 s, total: 14.3 s
Wall time: 3.76 s
show_topics(v, vocab)
['does like know space think just don people',
'file ftp nasa image files program thanks graphics',
'earth station lunar orbit moon shuttle launch nasa',
'vice queens sank manhattan bronx beauchaine tek bobbe',
'christ nasa believe atheism satan bible space jesus']
Implementing Randomized#
Q = np.random.randint(1,10, 9).reshape([3,3]); Q
Q = np.random.randn(3,3); Q
array([[-0.78584373, -1.15584006, 1.02165028],
[ 1.30688763, -2.40217237, -1.33608905],
[ 0.18773331, 0.2357126 , -1.24552412]])
Q.T
array([[-0.78584373, 1.30688763, 0.18773331],
[-1.15584006, -2.40217237, 0.2357126 ],
[ 1.02165028, -1.33608905, -1.24552412]])
Q@Q.T
array([[ 2.99728591, 0.38450186, -1.69246517],
[ 0.38450186, 9.26352133, 1.34325519],
[-1.69246517, 1.34325519, 1.64213456]])
A = np.random.normal(size=(10,9))
A.shape
(10, 9)
s = 3
size = (A.shape[1], s)
size
(9, 3)
Q = np.random.normal(size=size);Q.shape
(9, 3)
(A@Q).shape
(10, 3)
Q, tmp = sp.linalg.lu(A@Q, permute_l=True)
Q.shape
(10, 3)
tmp.shape
(3, 3)
A.shape, (A.T@Q).shape
((10, 9), (9, 3))
Q, tmp = sp.linalg.lu(A.T@Q, permute_l=True)
Q.shape
(9, 3)
Q, tmp = sp.linalg.qr(A@Q, mode='economic')
Q.shape
(9, 3)
tmp.shape
(3, 3)
tmp
array([[ 3.95035136, -3.38329669, -1.37453569],
[ 0. , 3.6106873 , 4.23593696],
[ 0. , 0. , -5.28262572]])
Q
array([[ 0.10075212, 0.21837398, 0.11792651],
[ 1. , 0. , 0. ],
[-0.03682198, 0.44183267, 1. ],
[-0.44080867, -0.37256568, 0.02324834],
[-0.70322551, -0.15386372, 0.21592698],
[ 0.08350268, -0.0905467 , 0.14158361],
[ 0.50762928, 0.84231332, 0.8683797 ],
[ 0.3939241 , 1. , 0. ],
[-0.96173764, 0.53149523, 0.20955641]])
def randomized_range_finder(A, size, n_iter=5):
Q = np.random.normal(size=(A.shape[1], size))
for i in range(n_iter):
Q, _ = sp.linalg.lu(A@Q, permute_l=True)
Q, _ = sp.linalg.lu(A.T@Q, permute_l=True)
Q, _ = sp.linalg.qr(A@Q, mode='economic')
return Q
n_components=5
n_oversamples=10
n_iter=4
vectors.shape
# M.shape
(2034, 26576)
n_random = n_components + n_oversamples
Q = randomized_range_finder(vectors, n_random, n_iter)
Q
array([[-0.02137672, 0.02867907, 0.00147528, ..., 0.01530008,
0.0131687 , -0.00112568],
[-0.01125351, -0.007019 , -0.00373134, ..., 0.00326252,
0.02130407, 0.01448943],
[-0.01073123, -0.00256461, -0.00537675, ..., 0.00307844,
-0.00575456, 0.0005117 ],
...,
[-0.0231287 , 0.03040804, 0.00351839, ..., 0.01126928,
0.05252739, -0.01553131],
[-0.03342604, -0.02780798, -0.02251785, ..., -0.07096806,
-0.00142386, -0.04975683],
[-0. , -0. , 0. , ..., -0. ,
-0. , 0. ]])
Q.shape
(2034, 15)
vectors.shape
(2034, 26576)
M = vectors.copy()
B = Q.T@M
B.shape
(15, 26576)
%time Uhat, s, V = sp.linalg.svd(B, full_matrices=False)
CPU times: user 54.3 ms, sys: 24.1 ms, total: 78.4 ms
Wall time: 24.8 ms
Uhat.shape, s.shape, V.shape
((15, 15), (15,), (15, 26576))
del B
U = Q@Uhat
U.shape
(2034, 15)
U[:,:n_components].shape
(2034, 5)
s[:n_components].shape
(5,)
V[:n_components,:].shape
(5, 26576)
def randomized_svd(M, n_components, n_oversamples=10, n_iter=4):
n_random = n_components + n_oversamples
Q = randomized_range_finder(M, n_random, n_iter)
B = Q.T@M
Uhat, s, V = sp.linalg.svd(B, full_matrices=False)
del B
U = Q@Uhat
return U[:,:n_components], s[:n_components], V[:n_components, :]
%time u, s, v = randomized_svd(vectors, 5)
CPU times: user 224 ms, sys: 131 ms, total: 355 ms
Wall time: 103 ms
u.shape, s.shape, v.shape
((2034, 5), (5,), (5, 26576))
show_topics(v, vocab)
['does like know space think just don people',
'file ftp nasa image files program thanks graphics',
'earth station lunar orbit moon shuttle launch nasa',
'vice queens sank manhattan bronx beauchaine tek bobbe',
'like values people moral just don morality think']
UV=u@s
# M_recon= US@V
# M_recon.shape
UV.shape
(2034,)
v.shape
(5, 26576)
M_recon = u@np.diag(s)@v
M_recon.shape
(2034, 26576)
np.linalg.norm(M-M_recon)
43.70003415792525