Naive Bayes
Contents
Naive Bayes#
Imports#
from fastcore.all import *
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import rich
from rich.console import Console
import nltk
from nltk.corpus import twitter_samples
import re # library for regular expression operations
import string # for string operations
from nltk.corpus import stopwords # module for stop words that come with NLTK
from nltk.stem import PorterStemmer # module for stemming
from nltk.tokenize import TweetTokenizer # module for tokenizing strings
import string
from matplotlib.patches import Ellipse
import matplotlib.transforms as transforms
sns.set()
console = Console()
console.print("Hello Naive Bayes", style='red')
Hello Naive Bayes
Download Dataset and Read Dataset#
nltk.download('twitter_samples')
nltk.download('stopwords')
[nltk_data] Downloading package twitter_samples to
[nltk_data] /home/rahul.saraf/nltk_data...
[nltk_data] Package twitter_samples is already up-to-date!
[nltk_data] Downloading package stopwords to
[nltk_data] /home/rahul.saraf/nltk_data...
[nltk_data] Package stopwords is already up-to-date!
True
ptweets = twitter_samples.strings('positive_tweets.json')
ntweets = twitter_samples.strings('negative_tweets.json')
df = pd.DataFrame({'positive':ptweets, 'negative':ntweets}).unstack().reset_index().drop(columns=['level_1']).rename(columns={'level_0':'class', 0:'tweets'})
df.head()
| class | tweets | |
|---|---|---|
| 0 | positive | #FollowFriday @France_Inte @PKuchly57 @Milipol... |
| 1 | positive | @Lamb2ja Hey James! How odd :/ Please call our... |
| 2 | positive | @DespiteOfficial we had a listen last night :)... |
| 3 | positive | @97sides CONGRATS :) |
| 4 | positive | yeaaaah yippppy!!! my accnt verified rqst has... |
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 10000 entries, 0 to 9999
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 class 10000 non-null object
1 tweets 10000 non-null object
dtypes: object(2)
memory usage: 156.4+ KB
Preprocessing#
tweet = df.loc[2277, 'tweets']; tweet
'My beautiful sunflowers on a sunny Friday morning off :) #sunflowers #favourites #happy #Friday off… https://t.co/3tfYom0N1i'
Clean & Stem Tweet#
def remove_old_style(tweet): return re.sub(r'^RT[\s]+', '', tweet)
def remove_url(tweet): return re.sub(r'https?://[^\s\n\r]+', '', tweet)
def remove_hash(tweet): return re.sub(r'#', "", tweet)
tokenizer = TweetTokenizer(preserve_case=False, strip_handles=True, reduce_len=True)
skip_words = stopwords.words('english')+list(string.punctuation)
stemmer = PorterStemmer()
def filter_stem_tokens(tweet_tokens, skip_words=skip_words, stemmer=stemmer):
return [ stemmer.stem(token) for token in tweet_tokens if token not in skip_words]
process_tweet = compose(remove_old_style, remove_url, remove_hash, tokenizer.tokenize, filter_stem_tokens)
process_tweet(tweet)
# skip_words
['beauti',
'sunflow',
'sunni',
'friday',
'morn',
':)',
'sunflow',
'favourit',
'happi',
'friday',
'…']
df['Ptweets'] = df['tweets'].apply(process_tweet)
# df['Ptweets_join'] = df['Ptweets'].apply(lambda row: u" ".join(row))
u':)'
':)'
tweet = df.loc[2277, "Ptweets"]
def check_token(tweet, token):
if token in tweet : return True
else: return False
token = ":)"
df[df['Ptweets'].apply(lambda row: check_token(row, token))]
| class | tweets | Ptweets | |
|---|---|---|---|
| 0 | positive | #FollowFriday @France_Inte @PKuchly57 @Milipol... | [followfriday, top, engag, member, commun, wee... |
| 1 | positive | @Lamb2ja Hey James! How odd :/ Please call our... | [hey, jame, odd, :/, pleas, call, contact, cen... |
| 2 | positive | @DespiteOfficial we had a listen last night :)... | [listen, last, night, :), bleed, amaz, track, ... |
| 3 | positive | @97sides CONGRATS :) | [congrat, :)] |
| 4 | positive | yeaaaah yippppy!!! my accnt verified rqst has... | [yeaaah, yipppi, accnt, verifi, rqst, succeed,... |
| ... | ... | ... | ... |
| 4996 | positive | @RachelLiskeard Thanks for the shout-out :) It... | [thank, shout-out, :), great, aboard] |
| 4997 | positive | @side556 Hey! :) Long time no talk... | [hey, :), long, time, talk, ...] |
| 4998 | positive | @staybubbly69 as Matt would say. WELCOME TO AD... | [matt, would, say, welcom, adulthood, ..., :)] |
| 6736 | negative | @Israelgirly They sure do, esp now when ppl ar... | [sure, esp, ppl, talk, crap, milli, >:(, i'll,... |
| 7244 | negative | @wtfxmbs AMBS please it's harry's jeans :)):):):( | [amb, pleas, harry', jean, :), ):, ):, ):] |
3543 rows × 3 columns
# df[df['Ptweets_join'].str.contains
Creating Freqeuncy Dataframe#
len(df['Ptweets'].sum())
68430
len(set(df['Ptweets'].sum()))
10507
def get_word_count(token):
d = df[df['Ptweets'].apply(lambda row: check_token(row, token))]['class'].value_counts().to_dict()
return {'word': token, 'positive':d.get('positive',0), 'negative':d.get('negative', 0)}
def build_freqs(df):
tokens = list(set(df['Ptweets'].sum()))
df_freqs = pd.DataFrame([get_word_count(token) for token in tokens]).set_index('word');
# Laplace smoothing formulae for probability
V = df_freqs.shape[0]
df_freqs['log_pos_prob'] = np.log((df_freqs['positive']+1)/(df_freqs['positive'].sum()+V))
df_freqs['log_neg_prob'] = np.log((df_freqs['negative']+1)/(df_freqs['negative'].sum()+V))
df_freqs['lambda'] = df_freqs['log_pos_prob'] - df_freqs['log_neg_prob']
return df_freqs
df_freqs = build_freqs(df)
# np.log(df_freqs['pos_prob'])
# good_keys = df.index.intersection()
# df_freqs.loc[good_keys]
l = df_freqs.head().index.tolist()
l.append("lalala")
df_freqs.loc[df_freqs.index.intersection(l)]
| positive | negative | log_pos_prob | log_neg_prob | lambda | |
|---|---|---|---|---|---|
| word | |||||
| sweden | 0 | 1 | -10.688279 | -9.972150 | -0.716129 |
| jackson | 0 | 3 | -10.688279 | -9.279003 | -1.409276 |
| gl | 1 | 0 | -9.995132 | -10.665298 | 0.670166 |
| shake | 2 | 1 | -9.589667 | -9.972150 | 0.382484 |
| hee | 1 | 0 | -9.995132 | -10.665298 | 0.670166 |
Extract Features from tweet#
tweet = df.loc[2277, "Ptweets"]
l = df_freqs.loc[tweet].sum().tolist()
l.append(1)
l
[4174.0, 119.0, -76.26418672683839, -96.03713892386281, 19.77295219702441, 1]
def score_tweet(tweet, df_freqs):
l = df_freqs.loc[df_freqs.index.intersection(tweet)].sum().tolist()
# Do intersection to take keys that exist in frequency table and skip which don't
l.append(1)
return l
tweet, score_tweet(tweet, df_freqs)
# df_freqs.loc[]
(['beauti',
'sunflow',
'sunni',
'friday',
'morn',
':)',
'sunflow',
'favourit',
'happi',
'friday',
'…'],
[4063.0,
107.0,
-60.290305886425145,
-77.27149318108225,
16.981187294657104,
1])
# This is a data leak . Build Frequency and scoring only on train_df
df['positive'], df['negative'],df['log_pos_prob'], df['log_neg_prob'], df['lambda'] , df['bias']=zip(*df['Ptweets'].map(lambda row : score_tweet(row, df_freqs)))
df['sentiment'] = 0
df.loc[df['class']=='positive', 'sentiment'] = 1
df.head()
| class | tweets | Ptweets | positive | negative | log_pos_prob | log_neg_prob | lambda | bias | sentiment | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | positive | #FollowFriday @France_Inte @PKuchly57 @Milipol... | [followfriday, top, engag, member, commun, wee... | 3737.0 | 69.0 | -47.021071 | -64.579054 | 17.557983 | 1 | 1 |
| 1 | positive | @Lamb2ja Hey James! How odd :/ Please call our... | [hey, jame, odd, :/, pleas, call, contact, cen... | 4448.0 | 473.0 | -107.276901 | -116.195717 | 8.918815 | 1 | 1 |
| 2 | positive | @DespiteOfficial we had a listen last night :)... | [listen, last, night, :), bleed, amaz, track, ... | 3728.0 | 159.0 | -58.478652 | -67.157334 | 8.678683 | 1 | 1 |
| 3 | positive | @97sides CONGRATS :) | [congrat, :)] | 3562.0 | 4.0 | -10.113069 | -19.133371 | 9.020302 | 1 | 1 |
| 4 | positive | yeaaaah yippppy!!! my accnt verified rqst has... | [yeaaah, yipppi, accnt, verifi, rqst, succeed,... | 3878.0 | 273.0 | -129.201531 | -141.211416 | 12.009885 | 1 | 1 |
df_freqs.sum()
positive 33332.000000
negative 32336.000000
log_pos_prob -104991.038240
log_neg_prob -104871.983649
lambda -119.054592
dtype: float64
Modeling#
df = pd.DataFrame({'positive':ptweets, 'negative':ntweets}).unstack().reset_index().drop(columns=['level_1']).rename(columns={'level_0':'class', 0:'tweets'})
df['Ptweets'] = df['tweets'].apply(process_tweet)
train_df = pd.concat([df[:4000],df[5000:9000]])
test_df = pd.concat([df[4000:5000],df[9000:10000]])
df_freqs = build_freqs(train_df)
df_freqs
| positive | negative | log_pos_prob | log_neg_prob | lambda | |
|---|---|---|---|---|---|
| word | |||||
| sweden | 0 | 1 | -10.638928 | -9.923462 | -0.715466 |
| jackson | 0 | 3 | -10.638928 | -9.230315 | -1.408613 |
| gl | 1 | 0 | -9.945780 | -10.616609 | 0.670828 |
| shake | 2 | 1 | -9.540315 | -9.923462 | 0.383146 |
| hee | 1 | 0 | -9.945780 | -10.616609 | 0.670828 |
| ... | ... | ... | ... | ... | ... |
| control | 1 | 2 | -9.945780 | -9.517997 | -0.427784 |
| 590 | 0 | 1 | -10.638928 | -9.923462 | -0.715466 |
| who' | 9 | 7 | -8.336343 | -8.537167 | 0.200825 |
| school' | 1 | 0 | -9.945780 | -10.616609 | 0.670828 |
| ladygaga | 0 | 1 | -10.638928 | -9.923462 | -0.715466 |
9162 rows × 5 columns
bd = train_df['class'].value_counts().to_dict()
bias = np.log(bd['positive']/bd['negative'])
bias
0.0
train_df['positive'], train_df['negative'], train_df['log_pos_prob'], train_df['log_neg_prob'], train_df['lambda'] , train_df['bias']=zip(*train_df['Ptweets'].map(lambda row : score_tweet(row, df_freqs)))
train_df['prediction'] = train_df['lambda']+bias > 0
train_df['actual'] = train_df['class'] == 'positive'
(train_df['actual'] == train_df['prediction']).mean() # accuracy
0.999
test_df['positive'], test_df['negative'], test_df['log_pos_prob'], test_df['log_neg_prob'], test_df['lambda'] , test_df['bias']=zip(*test_df['Ptweets'].map(lambda row : score_tweet(row, df_freqs)))
test_df['prediction'] = test_df['lambda']+bias > 0
test_df['actual'] = test_df['class'] == 'positive'
(test_df['actual'] == test_df['prediction']).mean() # accuracy
0.9985
Visualization#
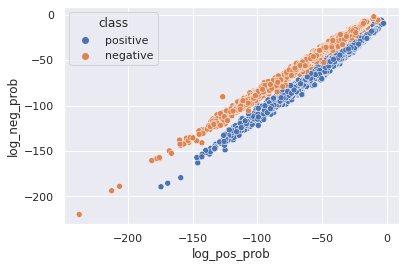
sns.scatterplot(data=train_df, x='log_pos_prob', y='log_neg_prob', hue='class')
<AxesSubplot:xlabel='log_pos_prob', ylabel='log_neg_prob'>
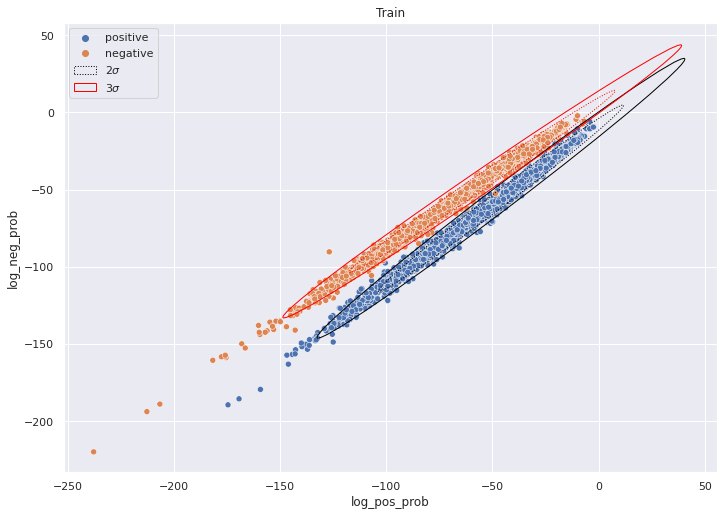
Confidence Elipse#
data_pos = train_df[train_df['class']=='positive']
data_neg = train_df[train_df['class']=='negative']
x = data_pos['log_pos_prob']
y = data_pos['log_neg_prob']
n_std=3.0
cov_mat= np.cov(x,y)
cov_mat
array([[832.64706392, 866.45359717],
[866.45359717, 911.72992453]])
pearson = cov_mat[0,1]/np.sqrt(cov_mat[0,0]*cov_mat[1,1])
pearson
0.994447194605905
ell_radius_x = np.sqrt(1+pearson)
ell_radius_y = np.sqrt(1-pearson)
ell_radius_x, ell_radius_y
(1.4122489846361743, 0.07451714832234908)
scale_x = np.sqrt(cov_mat[0,0])*n_std; mean_x = np.mean(x)
scale_x, mean_x
(86.56687342915261, -45.98846279441421)
scale_y = np.sqrt(cov_mat[1,1])*n_std; mean_y = np.mean(y)
scale_y, mean_y
(90.58459759147846, -55.61467522963381)
def calc_ellipses_data(x,y, n_std=3.0):
cov_mat= np.cov(x,y)
pearson = cov_mat[0,1]/np.sqrt(cov_mat[0,0]*cov_mat[1,1])
ell_radius_x = np.sqrt(1+pearson)
ell_radius_y = np.sqrt(1-pearson)
scale_x = np.sqrt(cov_mat[0,0])*n_std
mean_x = np.mean(x)
scale_y = np.sqrt(cov_mat[1,1])*n_std
mean_y = np.mean(y)
return ell_radius_x, scale_x, mean_x, ell_radius_y, scale_y, mean_y
calc_ellipses_data(x,y)
(1.4122489846361743,
86.56687342915261,
-45.98846279441421,
0.07451714832234908,
90.58459759147846,
-55.61467522963381)
def draw_ellipse(data, ax, facecolor='None', **kwargs):
ell_radius_x, scale_x, mean_x, ell_radius_y, scale_y, mean_y = data
ellipse = Ellipse((0, 0),
width=ell_radius_x * 2,
height=ell_radius_y * 2,
facecolor=facecolor,
**kwargs)
transf = transforms.Affine2D() \
.rotate_deg(45) \
.scale(scale_x, scale_y) \
.translate(mean_x, mean_y)
ellipse.set_transform(transf + ax.transData)
return ax.add_patch(ellipse)
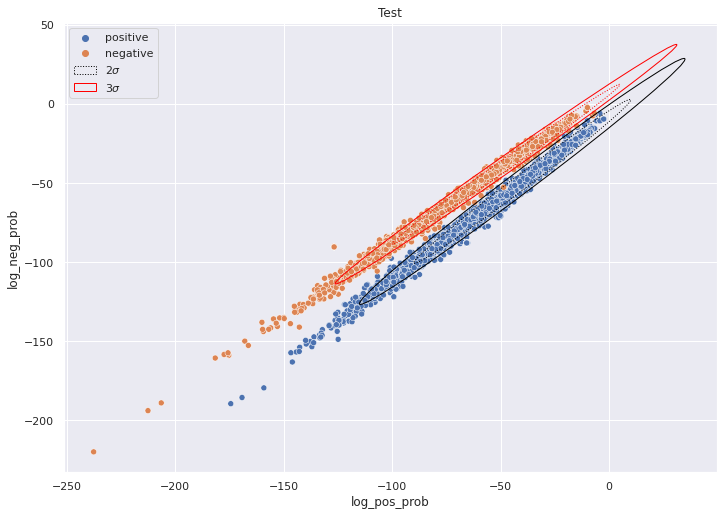
def plot_naive_bayes(df, ax=None, title='data'):
data_pos = df[df['class']=='positive']
data_neg = df[df['class']=='negative']
if ax is None:fig, ax = plt.subplots(figsize=(11.7, 8.27))
sns.scatterplot(data=train_df, x='log_pos_prob', y='log_neg_prob', hue='class', ax=ax)
x = data_pos['log_pos_prob']
y = data_pos['log_neg_prob']
ellipse_data_2std=calc_ellipses_data(x,y, n_std=2)
draw_ellipse(ellipse_data_2std, ax, edgecolor='black', linestyle=':',label=r'$2\sigma$')
ellipse_data_3std=calc_ellipses_data(x,y, n_std=3)
draw_ellipse(ellipse_data_3std, ax, edgecolor='black')
x = data_neg['log_pos_prob']
y = data_neg['log_neg_prob']
ellipse_data_2std=calc_ellipses_data(x,y, n_std=2)
draw_ellipse(ellipse_data_2std, ax, edgecolor='red', linestyle=':')
ellipse_data_3std=calc_ellipses_data(x,y, n_std=3)
draw_ellipse(ellipse_data_3std, ax, edgecolor='red',label=r'$3\sigma$')
ax.legend()
ax.set_title(title)
return ax
plot_naive_bayes(train_df, title='Train')
plot_naive_bayes(test_df, title='Test')
<AxesSubplot:title={'center':'Test'}, xlabel='log_pos_prob', ylabel='log_neg_prob'>